CS:APP malloc lab 프로젝트
소개
이 과제에서는 C 언어용 동적 메모리 할당기를 직접 구현합니다.
즉, malloc, free, realloc 루틴을 직접 설계하고 작성해야 합니다.
목표는 다음과 같습니다:
- 올바른 동작 (Correctness)
- 효율적인 메모리 사용 (Space Utilization)
- 빠른 처리 속도 (Throughput)
팀 구성
- 최대 2명까지 팀 구성 가능
- 공지 및 수정 사항은 웹페이지를 통해 안내됩니다
시작하기
- malloclab-handout.tar 압축 해제
tar xvf malloclab-handout.tar - 수정할 파일: mm.c
- 실행용 드라이버: mdriver.c
make ./mdriver -V
최종 제출 시 mm.c 파일 하나만 제출합니다.
구현해야 할 함수
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
- mm_init: 힙 초기화
- mm_malloc: 최소 size 바이트 블록 할당 (8바이트 정렬 보장)
- mm_free: 블록 해제
- mm_realloc: 블록 크기 조정
힙 일관성 검사기
int mm_check(void);
확인할 항목 예시:
- free 리스트에 있는 모든 블록이 실제로 free 상태인가
- 인접 free 블록이 병합되지 않고 남아 있지 않은가
- free 리스트의 포인터가 올바른 힙 주소를 가리키는가
- 블록이 겹치지 않는가
지원 루틴 (memlib.c)
- void *mem_sbrk(int incr): 힙 확장
- void *mem_heap_lo(void): 힙 시작 주소 반환
- void *mem_heap_hi(void): 힙 끝 주소 반환
- size_t mem_heapsize(void): 힙 크기 반환
- size_t mem_pagesize(void): 페이지 크기 반환
드라이버 프로그램 (mdriver.c)
드라이버는 trace 파일에 기록된 할당/재할당/해제를 실행하며 성능과 정확성을 평가합니다.
주요 옵션:
- -t <\dir>: trace 파일 위치 지정
- -f
: 특정 trace 파일만 실행 - -l: libc malloc과 비교 실행
- -v: 성능 요약 출력
- -V: 디버깅용 상세 출력
프로그래밍 규칙
- mm.c 인터페이스 변경 금지
- malloc, calloc, free, realloc, sbrk 등 시스템 호출 금지
- 전역 배열/구조체/리스트 선언 불가 (정수, 포인터 등 스칼라 변수는 가능)
- 항상 8바이트 정렬된 포인터 반환
평가 기준
- 정확성 (20점): 드라이버 테스트 통과 여부
- 성능 (35점)
- 메모리 활용도 (Space Utilization)
- 처리량 (Throughput)
- 성능 지수:
P = wU + (1-w)min(1, T/Tlibc)(기본 w = 0.6, Tlibc ≈ 600Kops/s)
- 스타일 (10점)
- 코드 구조, 주석, 일관성 검사기 품질
제출
최종적으로 mm.c 파일 하나만 제출합니다.
제출 방법은 강의 사이트 지침에 따릅니다.
힌트
- 작은 trace 파일(short1.rep, short2.rep)로 디버깅 시작
- -v, -V 옵션 활용
- gcc -g로 컴파일 후 gdb 디버깅
- 교재의 암시적 free list 기반 malloc 구현 이해
- 포인터 연산은 매크로로 캡슐화
- 단계별 구현: malloc/free 먼저, realloc은 나중에
- gprof 등 프로파일러 활용
- 일찍 시작하는 것이 중요
파일별 역할과 상호작용
크게 나누면 메모리 관리기 구현(mm.c), 드라이버/성능 평가(mdriver.c, fsecs, fcyc, clock 등), 메모리 시뮬레이터(memlib) 로 구분됩니다
메모리 관리기 구현
-
mm.c 학생이 직접 구현하는 malloc/free/realloc 패키지
-
매크로(WSIZE, DSIZE, HDRP, FTRP, NEXT_BLKP, PREV_BLKP)로 블록의 헤더/푸터와 연결을 조작
-
mm_init: 초기 힙 생성 (prologue, epilogue 블록 설정)
-
mm_malloc: 요청한 크기를 ALIGN 맞추고 블록을 할당
-
mm_free: 블록을 해제 후 coalesce(병합)
-
mm_realloc: 새로운 블록 할당 후 기존 데이터 복사 → 기존 블록 해제
-
extend_heap: 힙을 늘리고 coalesce 호출 즉, 학생이 작성한 동적 메모리 할당기 핵심
-
mm.h mm.c의 함수 프로토타입(mm_init, mm_malloc, mm_free, mm_realloc)과 팀 정보 구조체 team_t
메모리 시뮬레이터
-
memlib.c 실제 시스템 sbrk 대신 가상 힙 환경 제공:
-
mem_sbrk: 힙 확장
-
mem_heap_lo / mem_heap_hi: 힙 시작/끝 주소
-
mem_heapsize: 힙 크기 학생이 mm.c에서 사용하는 힙 관리 API
-
memlib.h 위 함수들의 선언.
드라이버 & 성능 측정
-
mdriver.c
-
주 실행 파일
-
trace 파일(.rep)을 읽어 mm_malloc, mm_free, mm_realloc 동작을 검증/측정
-
eval_mm_valid: 올바른 동작 검사 (중복, 경계 위반 등)
-
eval_mm_util: 메모리 utilization(공간 효율) 측정
-
eval_mm_speed: 성능(throughput) 측정
-
결과를 종합해 점수(perf index) 출력
-
config.h
-
trace 파일 경로, 성능 가중치(UTIL_WEIGHT=0.6), 정답 기준(libc malloc 성능), 힙 크기 상한(20MB) 정의
-
timing 방법 선택 (USE_FCYC, USE_ITIMER, USE_GETTOD)
시간/성능 측정 유틸
-
이 부분은 malloc 성능 평가용 타이머 라이브러리:
-
clock.c / clock.h
-
CPU cycle counter(rdtsc 등) 사용
-
start_counter, get_counter로 cycle 측정
-
mhz()로 CPU 주파수 추정
-
start_comp_counter, get_comp_counter는 타이머 인터럽트 보정
-
fcyc.c / fcyc.h
-
K-best 알고리즘으로 안정적인 cycle 측정
-
여러 번 실행해서 수렴할 때까지 최소 실행시간 측정
-
옵션: cache clear, interrupt 보정, sample 개수 등
-
ftimer.c / ftimer.h
-
gettimeofday나 Unix interval timer 기반 시간 측정
-
fcyc 못 쓰는 환경 대체
-
fsecs.c / fsecs.h
-
high-level wrapper
-
init_fsecs()에서 타이머 초기화
-
fsecs(f, argp)로 함수 실행 시간을 초 단위로 반환
-
내부적으로 fcyc/ftimer 호출
전체 흐름
-
mdriver 실행 → trace 파일 읽음 → mm.c 구현된 malloc 패키지 테스트
-
memlib → 실제 힙 대신 가상 힙 제공
-
fcyc/ftimer/fsecs/clock → 실행 시간, 효율성, 성능 측정
-
결과 출력 → correctness + utilization + throughput + perf index
요약:
-
핵심 구현: mm.c (학생 과제)
-
힙 환경 제공: memlib
-
성능/정확도 검증: mdriver + trace files
-
시간 측정: clock, fcyc, fsecs, ftimer
-
환경 설정: config.h
동적 메모리 할당
명시적 할당기 - 응용이 명시적으로 할당된 블록을 반환해 줄 것을 요구
- 응용 프로그램이 명시적으로 free를 호출해야 메모리가 반환됨
- 즉, malloc으로 가져온 건 반드시 free로 돌려줘야 함
- C의 malloc/free가 전형적인 명시적 할당기
묵시적 할당기 - 할당된 블록이 더 이상 프로그램에 의해 사용되지 않고 블록을 반환하는지를 할당기가 검출할 수 있을 것을 요구(가비지 컬렉터)
- 할당기가 스스로 쓸모없는 블록(garbage)을 찾아서 회수해야 함
- 즉, 프로그래머가 free 안 해도, 할당기가 프로그램 동작을 추적해서 “더 이상 안 쓰는 메모리”를 자동으로 회수.
- Java, Python, Go 같은 언어의 가비지 컬렉터(GC)가 이 역할
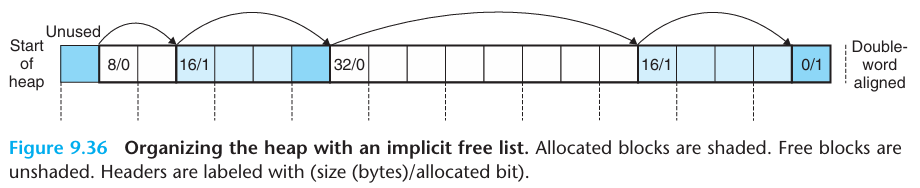
묵시적 가용 리스트 (Implicit Free List) 특징 - 모든 블록(할당된 것 + 가용한 것)을 연속적으로 나열해서 탐색. 각 블록에는 헤더(그리고 가끔 푸터) 가 있어서 블록의 크기와 할당 여부를 저장. malloc이 새 블록을 찾을 때는 힙의 처음부터 끝까지 순차적으로 돌면서 가용 블록인지 확인
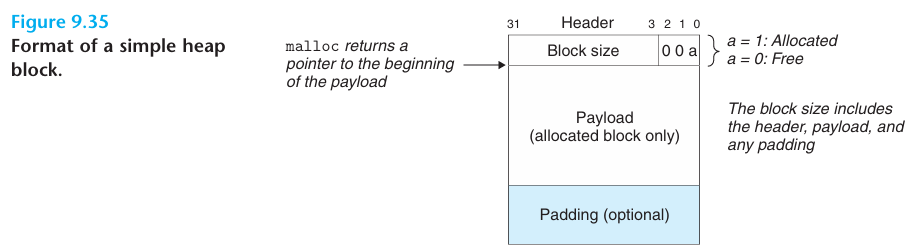
힙의 각 블록은 헤더(header), 페이로드(payload), 필요시 패딩(padding)으로 구성
- 헤더에는 블록 전체 크기(헤더+페이로드+패딩)와 할당 여부(allocated/free)가 기록
- 더블워드(8바이트) 정렬을 강제하면, 블록 크기는 항상 8의 배수가 되므로 블록 크기의 하위 3비트는 항상 0, 이 비트들을 “추가 정보 저장”에 활용할 수 있음 예를 들어 가장 낮은 비트 하나를 할당 여부 비트로 사용
- 블록 크기의 상위 29비트만 저장할 필요가 있고, 나머지 3비트는 다른 정보를 인코드하기 위해 남겨둠
- 패딩 하는 이유 - 외부 단편화 극복, 정렬 때문에
장점 - 구현이 단순하다 블록 헤더/푸터에만 정보가 있어서 구조가 간단하다. 단점 - 탐색 시간이 오래 걸림 → free 블록이 많아도, 할당된 블록까지 전부 훑어야 함 따라서 블록 수가 많아질수록 선형 탐색 비용 (O(n)) 발생.
명시적 가용 리스트 (Explicit Free List) 특징 - 가용 블록만 따로 연결 리스트로 관리. (할당된 블록은 리스트에 없음) 가용 블록마다 포인터 필드(전/후 연결)를 추가해서 더블 링크드 리스트 형태로 유지 따라서 malloc은 이 리스트만 돌면서 가용 블록을 찾음.
장점 - 탐색 범위가 훨씬 줄어듦 → 가용 블록만 관리하니까 성능 향상, 블록 삽입/삭제를 리스트 조작으로 할 수 있어 coalesce(병합)도 효율적, 다양한 변형 가능 (LIFO insert, segregated free list 등) 단점 - 블록 내부에 포인터 두 개(전/후)를 저장해야 해서 추가 메모리 오버헤드 발생, 구현이 더 복잡함
헤더 크기의 실제 값 워드 - 4바이트
malloc 함수
- 32비트 -> 8의 배수, 64비트 -> 16의 배수
- mmap, munmap, sbrk 함수를 사용
- sbrk 함수는 커널의 brk 포인터에 incr를 더해서 힙을 늘리거나 줄인다
- 성공하면 brk 값을 리턴하고 아니면 -1를 리턴하고 errno를 ENOMEM으로 설정
- 프로그램들은 할당된 힙 블록을 free 함수를 호출해서 반환
- 힙 블록을 free 함수를 호출해서 반환
-
ptr 인자는 malloc, calloc, realloc에서 할당된 블록의 시작을 가리켜야 한다
- 처리량 극대화하기
- 메모리 이용도를 최대화하기
단편화
- 내부 단편화 - 할당된 블록이 데이터 자체보다 더 클 때 일어난다
- 외부 단편화 - 할당 요청에 만족시킬 수 있는 메모리 공간이 전체적으로 존재하지만, 처리할 수 있는 단일한 가용블록은 없는 경우
구현 이슈
가용 블록 구성 - 가용 블록을 지속적으로 추적할것인가
배치 - 가용 블록을 어떻게 선택하는가?
분할 - 가용 블록에 배치한 후 가용 블록의 나머지 부분들로 무엇을 할 것인가?
연결 - 반환된 블록으로 무엇을 할것인가?
할당기의 배치 정책
- first fit, next fit, best fit
- first fit - 가용 리스트를 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택
- next fit - first fit과 비슷하지만 검색을 리스트의 처음에서 시작하는 대신, 이진 검색이 종료된 지점에서 검색을 시작
- best fit - 모든 가용 블록을 검사하며 크기가 맞는 가장 작은 블록을 선택
가용 블록과 free 블록 차이
둘 다 헤더(header)를 가진다 헤더에는
- 블록 전체 크기
- 할당 여부 비트
- 블록 크기는 항상 8바이트 단위 정렬
할당 블록
- 헤더의 할당 비트 = 1
- 내부 payload 영역이 사용자에게 반환
- payload 안에 사용자가 직접 저장한 데이터가 들어감
- 패딩은 정렬을 맞추기 위해 있을 수 있음
- 이 블록은 malloc에서 재사용 불가
Free 블록
- 헤더의 할당 비트 = 0
- 어떤 값이던지 무관
- 추가 메타데이터를 담는다(next/prev 포인터 저장)
- free 블록과 병합(coalescing)되어 더 큰 free 블록으로 확장
오류 단편화란?
-
외부 단편화, 내부 단편화
- 묵시적 가용 리스트 - 이전 블록이 free인지 알 수 없기 때문에 푸터가 필요
- 명시적 가용 리스트 - free 블록끼리 연결 포인터(next/prev)를 유지
- 분리 가용 리스트 - 크기별로 free 블록을 여러 리스트로 관리
함수 설명
mm_init()
- 힙 영역을 초기 상태로 세팅하는 함수
- mem_sbrk를 사용하여 초기 힙 공간을 가져옴
- 힙의 시작 부분에 프로롤로그(prologue) 블록과 끝에 에필로그(epilogue) 블록
- 프로롤로그 블록: 작은 크기의 “할당된 블록처럼 보이는” 더미 블록
- 에필로그 블록: 힙 끝에 위치하는 “크기가 0이고 항상 할당 상태인 헤더”
extend_heap()
- 힙 공간 확보 (mem_sbrk)
- 프로롤로그 블록 생성 (헤더/풋터에 “작은 크기 + 할당” 기록)
- 에필로그 헤더 생성 (크기=0, 할당됨)
- 초기 가용 블록 생성 (CHUNKSIZE만큼)
- free list 포인터 초기화 (명시적/분리 리스트일 경우)
언제 쓰는가?
- 힙이 초기화 될때
- mm_malloc이 적당한 맞춤 fit을 찾지 못할때
malloc()
- 사용자가 요청한 크기의 힙 블록을 정렬·오버헤드 반영 → 가용 블록 탐색 → 배치(place) → 필요 시 힙 확장의 순서로 처리
묵시적
- 메모리 블록과 매크로
- 블록 [헤더][payload][푸터] 구조, 헤더/푸터에는 “블록 전체 크기(8의 배수)”와 “할당비트(최하위 1비트)”가 저장됨
- PACK/GET/PUT, GET_SIZE/GET_ALLOC, HDRP/FTRP, NEXT_BLKP/PREV_BLKP로 헤더·푸터 접근과 이웃 블록 이동을 캡슐화
- [패딩][프롤로그 헤더(8,할당)][프롤로그 푸터(8,할당)][…가용/할당 블록들…][에필로그 헤더(0,할당)]
- 초기화
- mem_sbrk(4*WSIZE)로 최소 프레임 잡기
- 프롤로그(H/F)와 에필로그(H)를 세팅하고, heap_listp를 프롤로그 payload 시작으로 옮김
- extend_heap(CHUNKSIZE/WSIZE)로 처음 큰 가용 블록(보통 4KB)을 하나 만든 뒤, 에필로그를 그 뒤로 옮김
- save_bp = heap_listp; — next-fit의 시작 지점 저장
- 힙 확장
- 홀수→짝수 워드수로 맞춰 8바이트 정렬 유지
- mem_sbrk(size)로 힙 뒤에 새 영역 확보 → 그 영역을 가용 블록(H/F alloc=0)으로 만들고, 그 다음 위치에 새 에필로그 헤더(size=0, alloc=1)를 다시 세움
- 직전 블록이 가용이면 coalesce로 합쳐서 더 큰 가용 블록 반환
- 병합
- 앞/뒤 블록의 alloc 비트를 확인해서 4가지 경우:
- 앞/뒤 모두 할당 → 그대로 반환
- 앞 할당/뒤 가용 → “현재+뒤” 합치기
- 앞 가용/뒤 할당 → “앞+현재” 합치고 bp를 앞 블록 시작으로 이동
- 앞/뒤 모두 가용 → “앞+현재+뒤” 전부 합치고 bp를 앞 블록 시작으로 이동
- 합칠 때는 새 크기로 헤더와 푸터를 갱신
- 맞춤 정책
- first_fit: 힙 처음부터 순회하며 처음 맞는 가용 블록을 반환(코드는 정의돼 있지만 실제 사용은 하지 않음).
- next_fit: save_bp부터 끝까지 탐색 → 못 찾으면 힙 앞부터 save_bp 직전까지 다시 탐색. 찾으면 save_bp 갱신.
- 배치
- 선택된 가용 블록 크기 = csize, 필요 크기 = asize
- csize - asize >= 2*DSIZE(16)이면 분할: 앞쪽을 할당(H/F=1), 뒤쪽을 가용(H/F=0)으로 새 블록 생성 → save_bp는 남은 가용 블록으로
- 그렇지 않으면 통째로 할당(쪼가리(splinter) 방지) → save_bp = NEXT_BLKP(bp)
- (코드의 else 주석에 “남은 부분은 새로운 가용 블록”이라고 쓰였지만, 실제 동작은 “남김없이 전부 할당”이 맞음. 주석만 살짝 정정 필요)
- malloc
- size==0이면 NULL.
- 필요한 실제 블록 크기 asize 계산:
- 작은 요청(≤8바이트)은 최소 블록 16바이트(헤더/푸터 포함)로,
- 그 외엔 size + 헤더/푸터(=DSIZE)를 8바이트 배수로 올림 처리.
- next_fit(asize)로 가용 블록 탐색 → 있으면 place하고 그 bp 반환
- 없으면 extend_heap(MAX(asize, CHUNKSIZE)/WSIZE)로 힙 확장 후, 그 새 가용 블록에 place하고 반환.
- free
- 헤더/푸터의 alloc 비트를 0으로 바꿔 가용화
- coalesce로 인접 가용 블록들과 병합
- next-fit 재탐색 시 효율을 위해 save_bp를 병합 결과 위치로 갱신
- realloc
- 재할당 시 “가능하면 제자리에서(in-place), 안 되면 새로 할당+복사” 전략
- ptr==NULL → mm_malloc(size)와 동일
- size==0 → mm_free(ptr) 후 NULL
- old_block = GET_SIZE(HDRP(ptr)), old_payload = old_block - DSIZE 계산
- 새 asize를 구해 비교:
- 작아지는 경우(asize <= old_block): 같은 자리에서 place(ptr, asize)로 필요 시 분할(뒤쪽을 가용화). 복사 불필요.
- 커지는 경우: 바로 뒤 블록이 가용이고 old_block + next_size >= asize면,
- 헤더/푸터를 키워 제자리 확장 후, place(ptr, asize)로 필요 시 재분할 → 포인터 불변/복사 없음.
- 위가 안 되면 mm_malloc(size)로 새 블록 할당, min(old_payload, size)만큼 memcpy, 기존 블록 mm_free(ptr).
- 포인트: 에필로그는 alloc=1이므로 !GET_ALLOC(HDRP(next)) 조건에서 자동으로 제외되어 안전.
- 전형적인 호출 흐름(요약 시나리오)
- 프로그램 시작 → mm_init()이 프롤로그/에필로그 만들고 첫 가용 블록 확보
- 첫 mm_malloc(size) → next_fit에서 첫 가용 블록 발견 → place로 분할/할당
- 여러 번의 malloc/free 반복 → 가용 블록 조각화 발생 시 coalesce가 앞/뒤 블록을 합쳐 조각화를 줄임
- realloc이 크기 변경을 시도 → 가능하면 제자리 확대/축소, 불가하면 새 블록으로 이동+복사
할당 블록 vs 가용 블록
할당 블록(Allocated Block)
- 사용자에게 malloc/realloc으로 반환된 블록
헤더
- 크기(size) + alloc=1
- “이 블록은 사용 중” 표시
Payload
- malloc으로 반환된 주소
- 사용자가 자유롭게 씀
푸터
- 보통 성능 최적화를 위해 생략하기도 함 (internal fragmentation 줄이기 위함)
특징
- 연결 정보 없음 (free list에 들어가지 않음)
- 다른 free 블록과 coalesce 필요 없음
가용 블록(Free Block)
헤더
- 크기(size) + alloc=0
Payload 부분
- 사용자에게 반환되지 않고, 관리용 데이터 저장
- 일반적으로: Explicit free list → prev, next 포인터 저장
- Segregated list → 같은 크기 클래스의 링크 정보 저장
푸터
- 크기(size) + alloc=0
- 묵시적/명시적 리스트에서 coalesce 시 앞 블록 크기를 알기 위해 사용
특징
- free 블록끼리 리스트로 연결되어 있음
- coalesce 대상이므로 푸터를 주로 유지
테스트 케이스 점수항목
trace
- 몇 번째 trace 파일인지 (0번부터 시작). 각 trace 파일에는 malloc/free/realloc 연산들이 기록되어 있음
valid
- 해당 trace 를 실행했을 때 allocator 가 정상 동작했는지 여부 yes = 모든 요청이 올바르게 처리됨 (메모리 오버랩, 잘못된 free 같은 에러 없음) no = 오류 발생
util
- 메모리 공간 이용 효율(space utilization) = (프로그램이 실제로 필요했던 최대 메모리) ÷ (힙 전체 크기) 값이 높을수록 힙을 효율적으로 사용한 것
ops
- trace 안에 들어 있는 총 연산 수 (malloc/free/realloc 요청 개수)
secs
- 해당 trace 를 실행하는 데 걸린 실제 시간 (초) fsecs()/fcyc() 루틴을 사용해서 측정
Kops
- 처리 속도 - ops ÷ (secs × 1000) → 초당 천 단위 연산 수(Kilo-operations per second). 값이 클수록 throughput 이 좋음
소스 파일 내용 정리
WSIZE 4
DSIZE 8
메모리 블록 단위의 기본 크기
WSIZE 4
- 워드 크기
- 헤더와 푸터가 각각 4바이트를 차지하도록 설계
- WSIZE = 4 헤더/푸터의 크기 단위를 정의하는 값
DSIZE 8
- 더블워드 크기
- 정렬 - 모든 블록은 8바이트 경계에 맞춰야 함
- 64비트 시스템에서 포인터, long, double 같은 자료형들이 8바이트 단위로 정렬 되어야 성능 손실, 오류가 없음
CHUNKSIZE = (1 « 12)를 쓰는 이유
- OS 페이지 크기(4KB)에 맞추기 위해
- 작은 요청마다 시스템 호출하는 오버헤드를 줄이기 위해(미리 4KB 확보)
- 코드에서 페이지 크기 의미를 드러내기 위해
MAX(x,y) ((x) > (y) ? (x) : (y))
- x와 y를 비교하여 큰 값을 리턴
PACK(size, alloc) ((size) | (alloc))
- or 연산으로 두 비트를 합침
GET(p) ((unsigned int)(p))
- p를 unsigned int형으로 접근하여 값을 읽어옴
PUT(p, val)
- p를 unsigned int형으로 접근하여 val의 값을 저장
GET_SIZE(p)
- GET(p)를 해서 값을 읽어 온 후 하위 3비트를 버림
GET_ALLOC(p)
- GET(p)를 해서 값을 읽어 온 후 하위 1비트의 값만 가져옴
HDRP(bp)
- bp는 payload 주소, bp에서 1워드(WSIZE=4)만큼 뒤로 가면 헤더
((char*)(bp) - WSIZE)
FTRP(bp)
- bp에서 블록 크기만큼 이동하면 다음 블록의 payload 시작 주소
헤더(4B) + 푸터(4B) = 8B를 빼주면 현재 블록의 푸터 시작 주소를 가리키게 됨
((char*)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
NEXT_BLKP(bp)
- 현재 블록(bp)의 헤더를 참조해 블록 크기를 더하여 다음 블록의 payload 주소 반환
((char)(bp) + GET_SIZE(((char)(bp) - WSIZE)))
PREV_BLKP(bp)
- 현재 블록(bp)의 푸터를 참조해 블록 크기를 빼서 이전 블록의 payload 주소 반환
((char)(bp) - GET_SIZE(((char)(bp) - DSIZE)))
ALIGNMENT 8
- CPU가 데이터를 읽고 쓸 때, 특정 크기 단위의 주소에 맞춰져 있으면 빠르고 안정적이게 동작
- 모든 블록의 시작 주소는 반드시 8의 배수 주소가 되도록 맞추겠다
ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
- size를 8바이트 배수로 올림(ceil)하는 매크로
SIZE_T_SIZE (ALIGN(sizeof(size_t)))
- size_t -> 4바이트, size_t -> 8바이트, 어떤 환경이든 8바이트가 된다