..
스레드와 프로세스
-
프로세스와 스레드
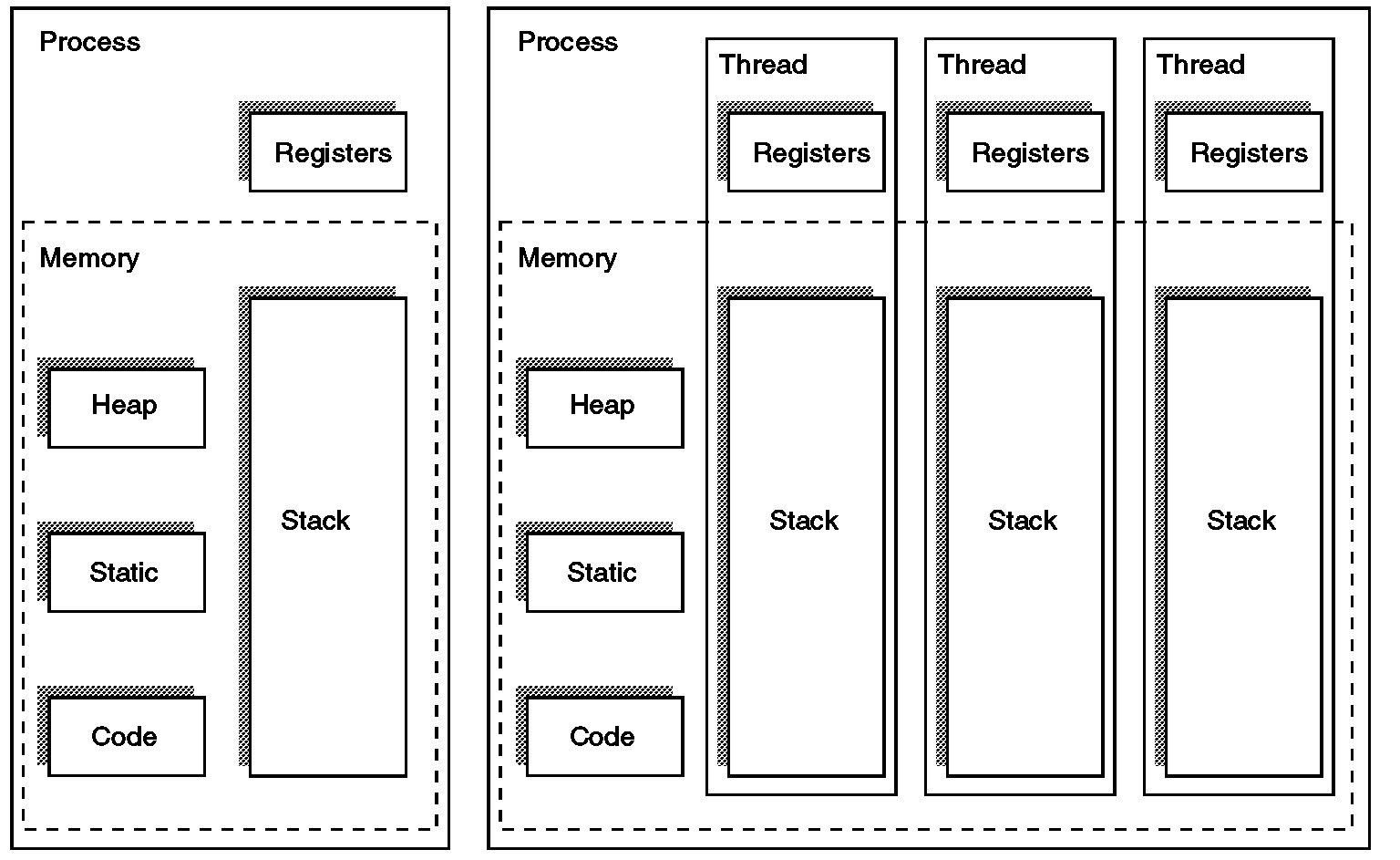
- 프로세스(Process)
- 운영체제에서 실행 중인 프로그램의 인스턴스
- 독립된 메모리 공간을 가짐 - Code, Data, Heap, Stack 영역
- 다른 프로세스와 주소 공간이 분리되어 있어 안전하지만, 통신(IPC)이 복잡함
- 스레드(Thread)
- 프로세스 내부에서 실행되는 흐름 단위
- 동일 프로세스의 Code, Data, Heap을 공유
- RIP(프로그램 카운터), RSP(스택 포인터), RAX/RBX/… 같은 레지스터 값들은 스레드마다 독립적으로 관리
- 각 스레드는 고유한 Stack을 가짐 -> 독립적인 함수 호출/지역변수 관리 가능
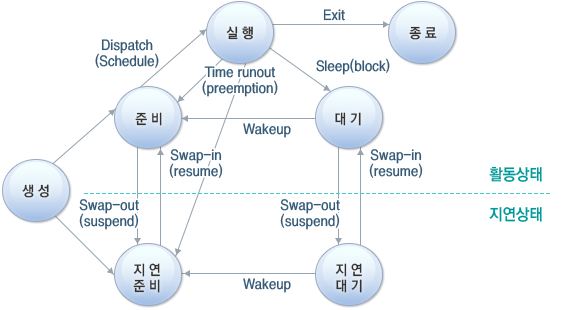
- 프로세스의 5가지 상태
- 생성(create) : 프로세스가 생성되는 중이다
- 실행(running) : 프로세스가 프로세서를 차지하여 명령어들이 실행되고 있다
- 준비(ready) : 프로세스가 프로세서를 사용하고 있지는 않지만 언제든지 사용할 수 있는 상태로, CPU가 할당되기를 기다리고 있다
- 대기(waiting) : 프로세스가 입출력 완료, 시그널 수신 등 어떤 사건을 기다리고 있는 상태를 말한다
- 종료(terminated) : 프로세스의 실행이 종료되었다
- 프로세스의 상태전이
- 디스패치(Dispatch) : 프로세스가 준비 상태에서 실행 상태로 전환되었다
- 타이머 런아웃(Timer Runout) : 프로세스가 실행 상태에서 준비상태로 전환되었다. 일반적으로 선점 프로세스에서 발생한다
- 블록(Block) : 프로세스가 자원 부족, I/O 입출력대기, 인터럽트 등 다른 사유에 의해 실행 상태에서 대기 상태로 전환되었다
- 활성화(Wake-up) : 프로세스가 부족한 자원을 재할당 받았다는 등의 사유로 대기 상태에서 준비 상태로 전환되었다
- 프로세스(Process)
-
프로그램과 프로세스 차이
- 프로그램(Program)
- 디스크에 저장된 정적인 실행 파일 (exe, out)
- 명령어와 데이터의 집합
- 프로세스(Process)
- 메모리에 로드되어 실제 CPU에서 실행되는 프로그램 인스턴스
- 실행 중인 프로그램
- 프로그램(Program)
-
스레드와 프로세스 차이
구분 프로세스 스레드 정의 실행 중인 프로그램 프로세스 내 실행 단위 메모리 독립적인 주소 공간 프로세스의 Code/Data/Heap 공유, Stack은 개별 통신 IPC 필요 (복잡, 느림) 공유 메모리로 간단히 통신 안정성 다른 프로세스 오류 영향 X 같은 프로세스 내 스레드 오류 시 전체에 영향 생성 비용 크다 (fork 등) 작다 (pthread_create 등) - 동시성과 병렬성
- 동시성(Concurrency)
- 여러 작업이 겉보기에는 동시에 실행되는 것
- 실제로는 CU가 매우 빠르게 Context Switching하며 번갈아 실행
- 단일 코어 스레딩, I/O 다중
- 병렬성(Parallelism)
- 물리적으로 여러 CPU 코어에서 동시에 작업 실행
- 멀티코어, 멀티프로세서 환경에서만 가능
- 멀티 코어 스레딩, 멀티 프로세싱
- 동시성(Concurrency)
- 스레드의 스케줄링
- 프로세스 내에서 실행되는 여러 스레드에 CPU를 분배하는 방식
- 운영체제보다 주로 라이브러리(pthread, JVM 등) 수준에서 관리됨
- 정책
- Round Robin: 순환하며 CPU 할당
- Priority Scheduling: 우선순위 높은 스레드 먼저 실행
- Work Stealing: 멀티코어에서 바쁜 스레드가 다른 큐에서 작업 훔치기
- 프로세스의 스케줄링
- OS 커널이 CPU를 프로세스들에게 분배하는 방식
- 정책
- FCFS(First Come First Serve): 도착 순서대로
- SJF(Shortest Job First): 실행 시간이 짧은 것 우선
- Round Robin: 시간 단위로 잘라 순환
- Priority Scheduling: 우선순위 기반
- Multilevel Queue / Feedback Queue: 여러 큐와 피드백을 통한 공정성 확보
- Context Switching 비용
- 프로세스 전환 시: PCB 저장/복원 + 주소 공간 전환(페이지 테이블 교체) → 비용 큼
- 페이지 테이블은 가상 주소를 물리 주소로 변환하기 위한 매핑 정보 저장소
- PCB(Process Control Block): 프로세스 하나하나의 상태를 기록해 두는 자료구조, PCB 저장/복원 = 프로세스의 “스냅샷”을 기록/재현하는 과정
- 스레드 전환 시: 같은 프로세스라 주소 공간 공유 -> 비용 작음
- 프로세스 전환 시: PCB 저장/복원 + 주소 공간 전환(페이지 테이블 교체) → 비용 큼
CPU 스케줄링
- 선점 스케줄링
- 운영체제가 CPU를 강제로 빼앗아서 다른 프로세스에게 넘겨줄 수 있는 방식
- 응답 속도가 빨라지고, 모든 프로세스가 공평하게 CPU를 쓸 수 있음
- Round Robin, SRTF(Shortest Remaining Time First)
- 비선점 스케줄링
- CPU를 잡은 프로세스가 스스로 끝낼 때까지 CPU를 계속 쓰는 방식. 운영체제가 중간에 뺏지 않음
- 문맥 교환이 적어서 단순하고 효율적임
- FCFS(First Come First Serve), SJF(Shortest Job First)
- 간트 차트
- 간트 차트(Gantt chart)는 프로젝트 일정관리를 위한 바 형태의 그래프

- 에이징(Aging)
- 기다린 만큼 우선순위 높아짐
- 기아현상
- 우선순위가 낮은 프로세스가 CPU 자원을 계속해서 할당받지 못하고 무한히 대기하는 상황
- FCFS(First Come First Serve, 비선점)
- 도착 순서대로 실행
- 단순함, 구현 용이, 문맥전환 적음
- 기아현상(Starvation) 없음
- 쓰이는 곳: 배치 작업, 디스크 I/O 큐의 일부 정책 등 단순·예측 가능한 환경
- SJF(Shortest Job First, 비선점)
- 실행 시간이 가장 짧은 작업부터
- SRTF(Shortest Remaining Time First, 선점)
- 남은 시간이 가장 짧은 작업을 항상 우선
- 쓰이는 곳: 짧은 작업 위주 서버, 빌드 파이프라인의 소작업
- Priority Scheduling (우선순위 스케줄링, 선점/비선점 모두 가능)
- 우선순위 수치가 높은 작업을 먼저 실행
- Round Robin (선점, 타임 슬라이스)
- 고정 시간 할당량(퀀텀) 만큼 돌아가며 실행
- Multilevel Queue (MLQ)
- 성격이 다른 작업을 여러 고정 큐로 분리하고, 큐 간 우선순위를 둔다
- Multilevel Feedback Queue (MLFQ)
- 동적으로 우선순위를 조정하는 다단계 큐
- Work Stealing (멀티코어 런타임 스케줄링)
- 각 코어가 자신의 deque에 작업을 가지고 있고, 할 일이 없어지면 다른 코어의 데크에서 훔쳐온다
레이스 컨디션(Race Condition)
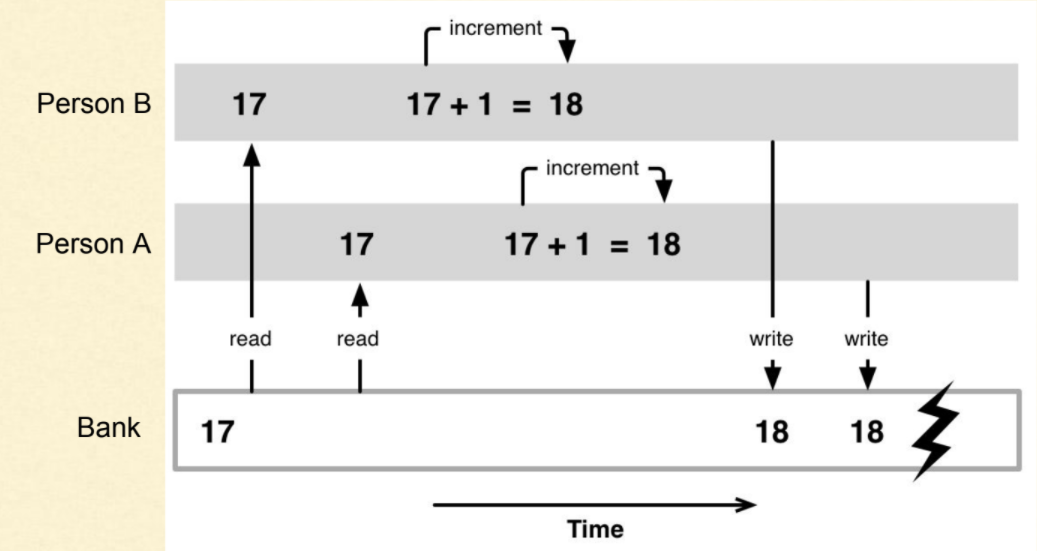
- 두 개 이상의 스레드가 동시에 같은 자원에 접근할 때, 실행 순서에 따라 결과가 달라질 수 있는 상태
-
공유 데이터에 접근하여 동시에 해당 데이터를 변경하려고 할 때 발생
- Critical Section
- 공유 자원에 접근하는 코드 구간, 이 구간을 원자적(atomic)으로 보장하지 않으면 레이스가 생김
- 원자적(Atomic)
- 연산이 도중에 끊기지 않고 한 번에 수행된다는 의미
- 원자적 보장이 없으면, 한 스레드가 값을 읽는 도중에 다른 스레드가 값을 바꿔서 예상치 못한 결과가 발생
- 레이스 컨디션 방지법
- 락(Lock) 이용 - 뮤텍스
- 올바른 동기화(Synchronization) - 세마포어
- 우선순위 관리(Priority Management)
뮤텍스
- Mutual Exclusion -> 상호 배제의 줄임말
- 한 번에 하나의 스레드만 critical section에 진입하게 하는 락
- 동작 방식
- 잠금 요청 - 어떤 스레드가 뮤텍스를 획득하면, 다른 스레드는 뮤텍스가 풀릴 때까지 대기
- 자원 사용
- 잠금 해제 - 뮤텍스를 반납하면, 대기 중인 다른 스레드 중 하나가 자원을 획득
- 뮤텍스의 특징
- Binary lock (0 또는 1의 상태만 가짐)
- 뮤텍스를 획득한 스레드만 해제할 수 있음 → 세마포어와의 중요한 차이점
- 일반적으로 블로킹 방식 (잠금이 안 풀리면 스레드는 sleep 상태)
- 잘못 사용하면 데드락 발생 가능, 두 스레드가 서로가 가진 뮤텍스를 기다리는 상황
long long counter = 0;
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&mtx);
counter++; // 공유 데이터 수정
pthread_mutex_unlock(&mtx);
데드락
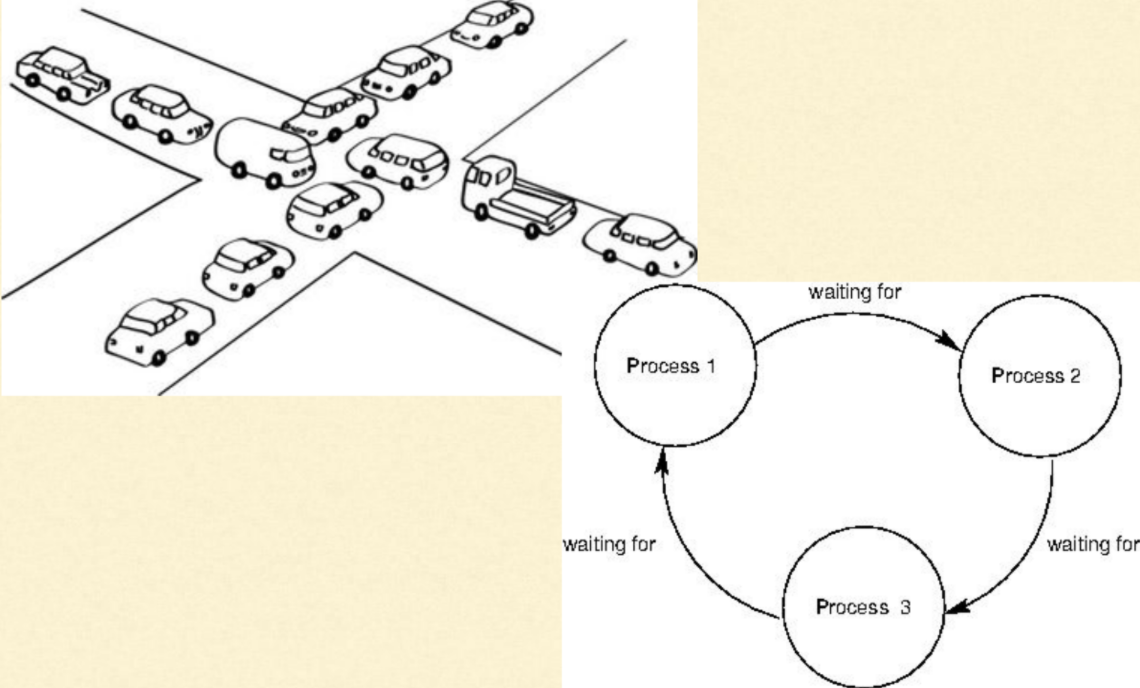
-
두 개 이상의 스레드가 서로가 보유한 자원을 기다리면서 영원히 블록된 상태
-
조건(Coffman’s Conditions, 네 가지 모두 성립해야 함)
- 상호 배제(Mutual Exclusion) – 자원은 동시에 하나만 사용 가능
- 점유와 대기(Hold and Wait) – 이미 자원을 가진 상태에서 다른 자원을 기다림
- 비선점(Non-preemption) – 자원을 강제로 뺏을 수 없음
- 순환 대기(Circular Wait) – 여러 프로세스가 원형으로 서로의 자원을 기다림
- 기아상태와의 차이점
- 우선순위 정책이나 스케줄링 방식 때문에 계속 뒤로 밀려서 실행 기회를 영원히 얻지 못하는 것
세마포어
- 공유 자원 접근을 제어하는 카운터 기반 동기화 도구
- 내부에 정수 카운터를 가진 동기화 도구
종류
- 카운팅 세마포어(Counting Semaphore)
- 0 이상의 정수 값을 가짐
- 값이 0보다 크면, 자원이 남아 있음을 의미 → 접근 가능
- 값이 0이면, 자원이 없음 → 대기해야 함
- 이진 세마포어(Binary Semaphore)
- 값이 0 또는 1만 가짐
- 사실상 뮤텍스(lock/unlock) 역할과 비슷함
동작 원리
- P() (Proberen, wait 연산): 세마포어 값을 1 줄임. 값이 음수가 되면 대기 상태로 전환
- V() (Verhogen, signal 연산): 세마포어 값을 1 늘림. 대기 중인 프로세스/스레드가 있으면 깨움