컴퓨터 구조 CS:APP 2장
Index
정보의 표현과 처리
이 글은 Randal E. Bryant와 David R. O’Hallaron의 저서 《Computer Systems: A Programmer’s Perspective》(CS:APP)를 참고하여 작성되었습니다.
정보의 저장과 처리를 위한 기계를 만들때는 이진수 값들이 더 잘 동작함
두 개의 값을 갖는 신호는 펀치카드에 구멍이 뚫렸는지, 막혔는지, 전선에 높은 전압이 걸리는지
낮은 전압이 걸리는지, 자기장이 시계 방향인지, 반시계 방향인지 같은 예가 있음
비트들을 묶어서 다른 가능한 비트 패턴에 의미를 부여하도록 특정 해석 방법을 적용하면,
어떤 유한집합의 원소들을 표시할 수 있게 된다
표준 문자코드를 사용해서 문자의 글자와 기호를 인코딩할 수 있음
양수들 간의 곱은 항상 양수이지만, 오버플로우인 경우에는 +∞를 만든다
부동소수점 연산은 수의 제한된 정밀도 때문에 교환법칙 성립 안함
부동소수점 표시는 넓은 범위의 값을 근사값으로만 인코딩해야 함
다른 사람들의 시스템에 불법적으로 접근하기 위해 가능한 모든 버그들을 활용하려는
해커부대가 존재한다 프로그래머들은 자신의 프로그램이 어떻게 동작하고
어떻게 원하지 않는 방향으로 동작하게 될 수 있는지 이해할 책임이 있다
산술식 계산 성능을 최적화하기 위해 컴파일러가 만들어 내는 기계어 코드를 이해하는 데 중요
정보의 저장
각 비트들에 접근하는 방식 대신에 컴퓨터들은 메모리에서 주소지정이 가능한
8비트 단위의 블록인 바이트를 사용한다
기계수준의 프로그램은 메모리를 가상 메모리라고 하는 거대한 바이트의 배열로 취급
메모리의 각 바이트는 주소라고 하는 고유한 숫자로 식별할 수 있음
모든 가능한 주소들의 집합을 가상 주소라고 함
C에서 어떤 포인터의 값은 저장장치의 동일한 블록의 첫 바이트의 가상주소가 된다
C 컴파일러는 각 포인터와 타입 정보를 연관시켜서 포인터가 지시하는 위치에
저장된 값에 접근하기 위해 그 값의 타입에 따라 다른 기계수준 코드를 생성할 수 있음
C 컴파일러가 타입 정보를 관리하지만 컴파일러가 생성하는 실제 기계수준 프로그램은
데이터 타입에 대한 정보를 전혀 가지고 있지 않다
기계수준의 프로그램은 각 프로그램의 객체를 단순히 바이트들의 블록으로 취급
프로그램 자신은 바이트의 연속으로 취급함
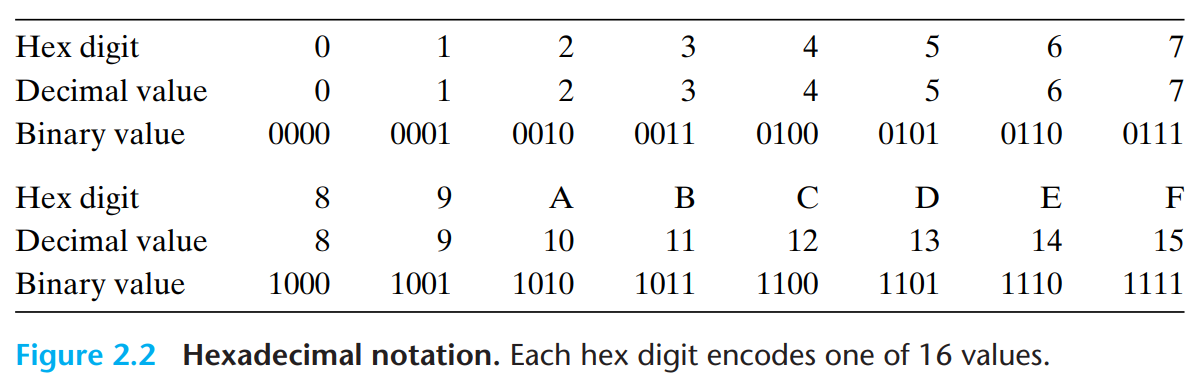
16진수 표시
16진수(hex)는 ‘0’에서 ‘9’까지의 숫자와 ‘A’에서 ‘F’까지 문자를 사용해서 16개의 가능한 값을 나타냄
16진수로 표시할 때, 하나의 바이트 값은 00(16진수)에서 FF(16진수)까지 범위를 갖는다
C에서 0X나 0x로 시작하는 숫자 상수들은 16진수로 해석한다
4비트씩 나누어 16진수로 변환하면 된다
비트들의 수가 4의 배수가 아니면 맨 왼쪽의 비트 그룹을 앞에 0을 추가해서 4의 배수로 만들어야 함
각 4비트씩의 그룹들을 대응하는 16진수로 번역함


접두어
- (8진수 - > 0o, 16진수 -> 0x, 2진수 -> 0b)
16진수 0x25B9D2 -> 이진수 (0b 0010 0101 1011 1001 1101 0010)
2 5 B 9 D 2 (0010 0101 1011 1001 1101 0010)
2진수 1010111001001001 -> 16진수 (0xAE49)
A E 4 9 (1010 1110 0100 1001)
x가 2의 배수일때 이진수를 16진수로 바꾸는 법 (n = i + 4 × j)
4비트(4자리 이진수) = 1자리 16진수
x = 2048 = \(2^{11}\)일때
-
n = 11 = 3 + 4 * 2이므로 i = 3, j = 2
-
앞자리는 i = 3이므로 8, 뒤에는 0이 2개 -> 0x800
십진수를 16진수로 변환하는 법
십진수 x를 16진수로 변환하기 위해서 x를 16으로 반복해서 나누고, 몫 q와 나머지 r을 얻는다
x = q * 16 + r로 표시된다
r을 최종 중요 숫자(Least Significant Digit)로 사용하고 q에 대해 이 과정을 반복한다
314,156 = 19,634 * 16 + 12 (C)
19,634 = 1,227 * 16 + 2 (2)
1,227 = 76 * 16 + 11 (B)
76 = 4 * 16 + 12 (C)
4 = 0 * 16 + 4 (4)
0x4CB2C로 바꿀 수 있다
Index
데이터의 크기
모든 컴퓨터는 워드 크기(word size)를 규격으로 갖는다
이것은 포인터의 정규 크기를 표시함
하나의 가상주소 = 한 개의 워드로 인코딩되기 때문임
시스템의 워드 크기는 가상 주소공간의 최대 크기를 결정함
w 비트 워드 크기 -> 컴퓨터의 가상주소는 0 ~ \(2^w - 1\)
프로그램은 최대 \(2^w\) 바이트에 접근 가능
32비트의 워드 크기의 가상 주소공간의 크기를 4기가 바이트(\(4 * 10^9\))
64비트 워드 크기로 확장되면서 16엑사 바이트 (\(1.84 * 10^{19}\))의 가상 주소공간으로 확장됨
대부분 64비트 컴퓨터들은 역방향 호환성을 가지고 있어서 32비트 머신들을 위해 컴파일된 프로그램도 실행 가능
프로그램이 어떻게 컴파일되었는가에 따라 “32비트 프로그램” 또는 “64비트 프로그램”이라고 부름
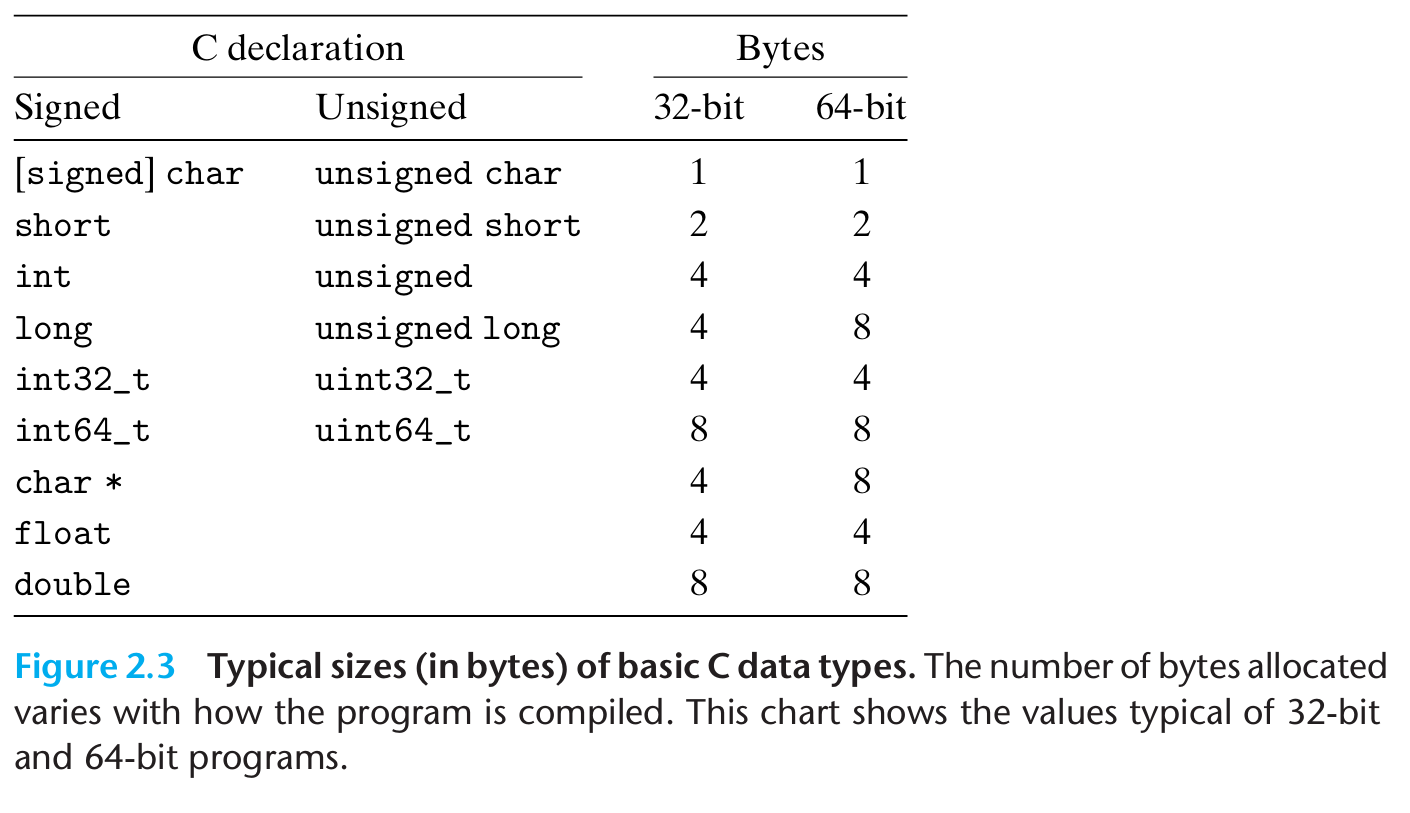
C언어의 데이터 타입들과 할당되는 바이트의 수를 그림과 같이 표현
정수 데이터는 0과 음수, 양수를 표시하기 위해서 부호형(signed)와 비부호형(unsigned) 정수가 될 수 있다
long은 32비트 프로그램에서는 대개 4바이트이고 64비트 프로그램에서는 8바이트
예측하지 못한 문제들을 피하기 위해 ISO C99는 컴파일러와 컴퓨터 설정에 관계없이 데이터 크기가 고정된 자료형들을 제안
int32_t와 int64_t는 각각 정확히 4바이트와 8바이트 크기를 갖는다
프로그래머는 1바이트 부호형 값을 보장하기 위해서는 signed char 선언을 사용해야 함, char 자료형이 부호형인지 여부는 프로그램의 동작에 영향을 주지 않음
unsigned long = long unsigned
대부분의 컴퓨터들은 두 개의 서로 다른 부동소수점 형식을 지원한다
C에서는 float으로 선언하는 단일정밀도, double로 선언하는 이중정밀도, 각각 4바이트, 8바이트를 사용한다
C언어 표준은 데이터 타입들이 표시할 수 있는 최저 한계값을 지정하고 있으나, 상위 한계값은 정의하지 않는다
64비트 머신들로의 전환이 이루어짐에 따라 프로그램들을 옮기는 과정에서 워드 크기 의존성들이 버그로 발생되었다
주소지정과 바이트 순서
거의 모든 컴퓨터에서 멀티 바이트 객체는 연속된 바이트에 저장되며, 객체의 주소는 사용된 바이트의 최소 주소로 정함
가장 중요한 비트 = Most Significant Bit
어떤 컴퓨터들은 객체를 메모리에 가장 덜 중요한 바이트부터 저장하며, 어떤 컴퓨터들은 가장 중요한 바이트부터 저장
가장 덜 중요한 바이트가 먼저 오는 것 - 리틀 엔디안 (대부분의 인텔 호환 머신)
가장 중요한 바이트가 먼저 오는 것 - 빅 엔디안 (IBM, Oracle)
리틀 엔디안이나 빅 엔디안이라는 용어는 걸리버 여행기에서 따온 것
바이트 순서 관습을 다른 관습 대신에 선택해야 하는 기술적 이유는 없다
-
문제가 되는 경우?
-
이진 데이터가 네트워크를 통해 다른 컴퓨터로 전송될 때
이러한 문제들을 피하기 위해서 송신 측 컴퓨터가 내부 표시를 네트워크 표준으로 변경
수신 측 컴퓨터가 네트워크 표준을 자신의 내부 표시방식으로 변환하도록 하는 관습을 따라야 한다
-
정수 데이터를 나타내는 바이트들을 살펴볼 때
-
정상적인 타입 체계를 회피하도록 작성되었을 때
- 캐스트나 유니온을 사용해서 객체가 만들어졌을 때와는 다른 타입의 데이터로 참조될 수 있도록 할 수 있음
-
포인터는 운영체제에 따라서 4바이트 주소와 8바이트 주소를 사용한다
Index
스트링의 표시
C에서 스트링은 널(값 0을 갖는) 문자로 종료하는 문자열로 인코딩된다
ASCII를 문자코드로 사용하는 모든 컴퓨터에서 바이트 순서나 워드 크기와 무관하게 똑같이 얻을 수 있다
텍스트 데이터는 이진 데이터보다 플랫폼 독립적이다
코드의 표현
int sum(int x, int y) {
return x + y;
}

인스트럭션들의 인코딩이 모두 다르다는 것을 알 수 있음
이진 코드는 컴퓨터와 운영체제들의 여러 가지 조합들 간에 호환성을 갖는 경우가 드물다
컴퓨터는 디버깅 시 도움을 주기 위해 관리하는 일부의 보조용 표를 제외하고는
본래의 소스 프로그램에 대한 정보를 전혀 가지고 있지 않다
부울 Boolean 대수
1850년경 George Boole(1815 ~ 1864)의 연구결과로 부울 대수(Boolean algebra)가 있다
Boole은 이진수 값 1과 0을 논리값 TRUE와 FALSE로 인코딩하면 논리 추론의 기본 원리들을
구현할 수 있는 대수학을 수식화할 수 있다는 점을 발견하였다
~P는 P가 참이 아니라면 참이 되고, 그 반대도 마찬가지다
P가 참이고 Q가 참일 때, P & Q도 참이고 P | Q도 참이다
(XOR) exclusive or은 P 혹은 Q가 둘 중에 참이 있으면서, 양쪽 모두가 참이 아닌 경우만 참이다

비트 벡터 마스크(mask)라는 것을 설정해서 특정 시그널을 선택적으로 활성화 또는 비활성화 할 수 있다
C에서의 비트수준 연산
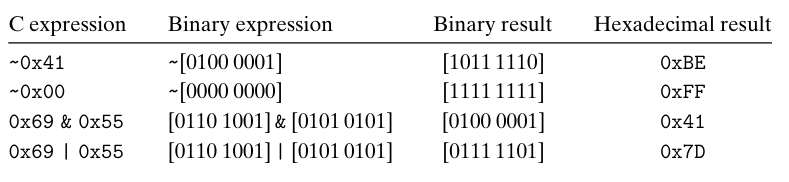
예제에서 보는 것처럼 비트수준 수식의 효과를 알 수 있는 가장 좋은 방법은
16진수 인자들을 이진수로 표시 확장해서 이진수에서 연산을 실행하고 다시 16진수로 변환하는 것이다
비트수준 연산은 마스크 연산을 구현할 때 사용한다
비트수준 연산 x&0xFF는 다른 바이트는 0으로 하고, x의 가장 덜 중요한 바이트만으로 구성된 값을 나타냄
-
& 연산
0x89ABCDEF
0x000000FF
————
0x000000EF
C에서의 논리 연산
논리 연산은 0이 아닌 인자들을 참으로 취급하고 0은 거짓으로 처리한다
논리 연산자와 비트 연산자의 중요한 차이는 수식의 결과가 첫 번째 인자를 계산해서 결정될 수 있으면
두번째 인자는 계산하지 않는다는 것이다
예를 들면 a가 0일때, a && 5/a는 0으로 나누기(division by zero) 오류를 절대 발생시키지 않으며
식 p && *p++은 널 포인터의 역참조를 절대 발생시키지 않는다
C에서의 쉬프트 연산
C는 비트 패턴을 좌우로 이동시키는 쉬프트 연산 집합을 제공한다
x « k는 x는 좌측으로 k비트 이동하고, 중요한 좌측의 k비트가 밀려서
삭제되며 우측에는 k개의 0으로 채워진다
C 언어에서는 우측 쉬프트 연산 x » k가 있다
-
논리 우측 쉬프트 : 좌측 끝에 k개의 0들로 채워서 만든다
-
산술 우측 쉬프트 : 좌측 끝에 가장 중요한 비트를 k개 반복해서 채워서 만든다
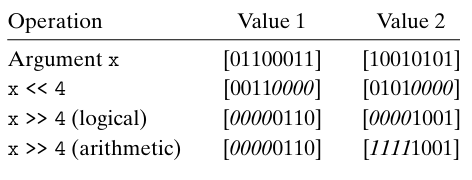
C 표준은 어떤 타입의 우측 쉬프트가 사용되어야 하는지 명확히 정의하고 있지 않음
많은 컴파일러들은 부호형 데이터에 대해서 산술 우측 쉬프트를 사용하고 있으며,
비부호형 데이터에 대해서는 우측 쉬프트는 논리 쉬프트여야 한다
부호형(signed) - 산술 우측 쉬프트 (부호 비트로 채움)
비부호형(unsigned) - 논리 우측 쉬프트 (0으로 채움)
Index
정수의 표시
두 가지 방법이 있다
양수만 표시할 수 있는 방법과 음수, 0, 양수 모드를 표시할 수 있음
정수형 데이터 타입
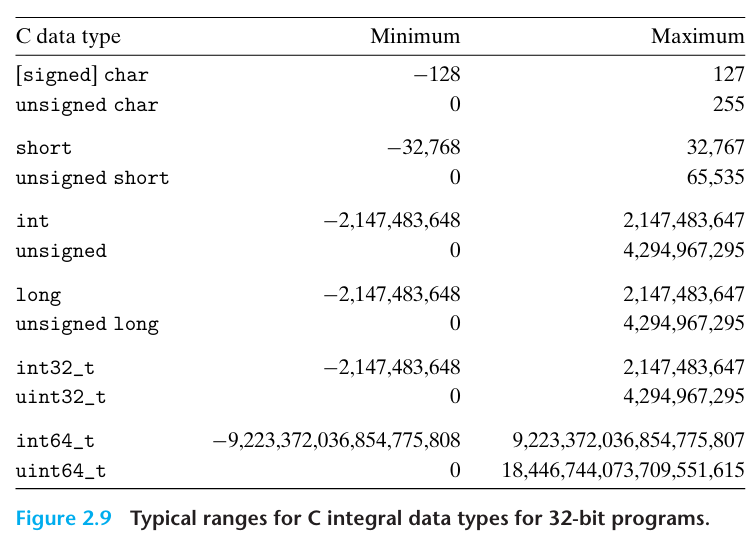
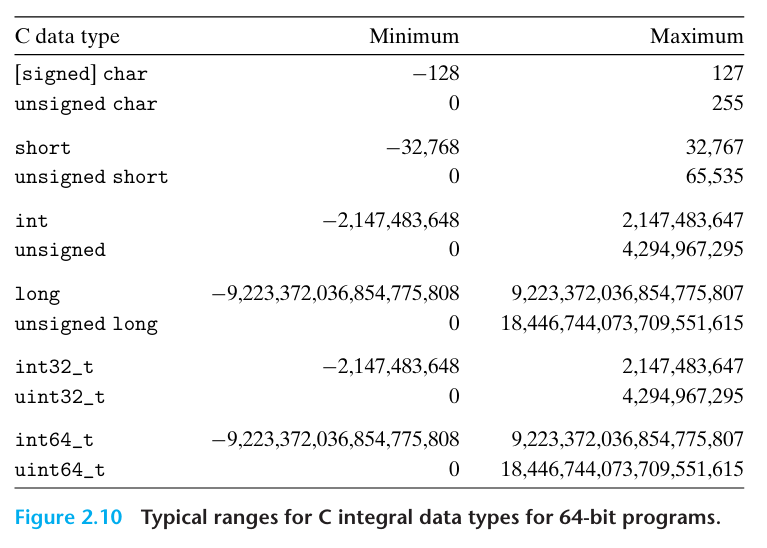
long은 64비트에서 8바이트를 사용하며 32비트에서 4바이트를 사용한다
음수의 범위가 양의 범위보다 1 더 넓다
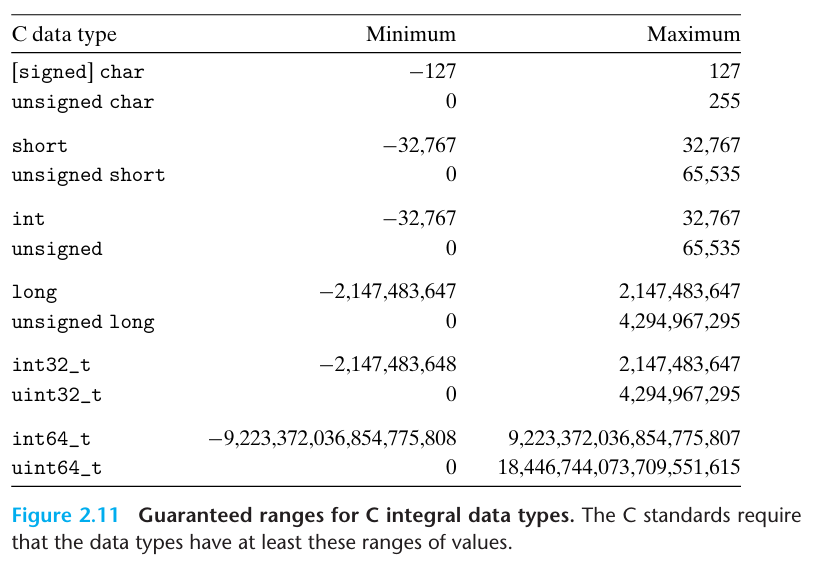
C 표준은 자료형들이 최소한 이 범위의 값을 가질 것을 요구한다
특히 고정길이 자료형들을 제외하고, 이들은 양과 음의 숫자들이 대칭적인 범위만을 갖도록 요구하고 있다
int는 16비트 머신 시절로의 회귀가 될지라도 2바이트 숫자들을 구현될 수 있음
long도 마찬가지로 4바이트로 구현될 수 있음
음수가 하나 더 큰 이유는 0이 양수 자리를 하나 더 차지하기 때문이다
실제 0은 양수도 음수도 아니지만 부호 비트 때문에 0은 양수에 포함된다
비부호형의 인코딩
B2U(w)(길이 w의 binary에서 unsigned로를 의미)로 나타낸다
비부호형 이진수 표시는 0과 \(2^w - 1\) 사이의 모든 숫자가 w비트 값으로 유일한 인코딩을 갖는다
함수 B2U(w)는 전단사 bijection 특성을 갖는다
전단사 특성의 수학적 의미는 어떤 함수 f가 양방향으로 사상할 수 있다는 것을 말한다 (1:1 대응)
2의 보수(two’s complement) 인코딩
부호형 숫자를 컴퓨터에서 표시하는 가장 일반적인 방법은 2의 보수 형식
B2T(w)(Binary to Two’s complement)와 같이 나타낸다
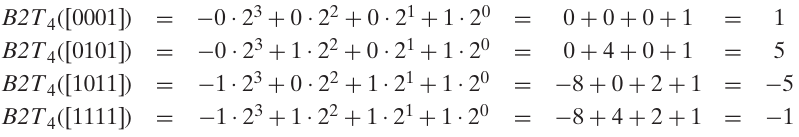
0001의 2의 보수 -> 1110 (1의 보수) -> 1111 (2의 보수)
1111는 -1이다 (1000 = -8, 1001 = -7 … 1111 = -1)
혹은, 각 자리수의 가중치를 더하는 방법이 있다
\[-0*2^3 + 0*2^2 + 0*2^1 + 1*2^0 = 1\]
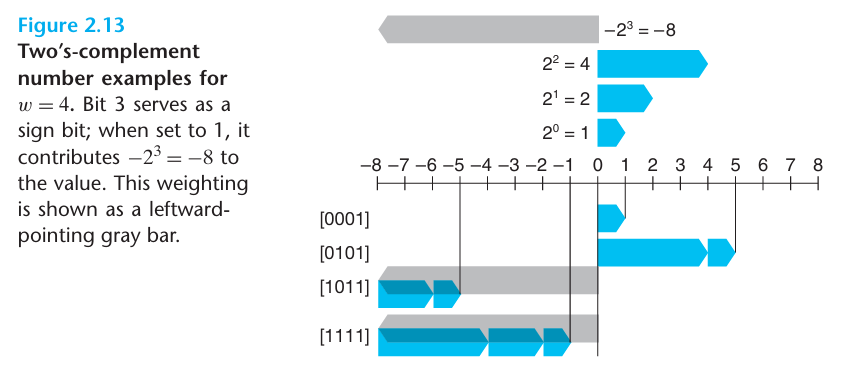
함수 T2B(w)는 B2T(w)의 역함수이다
2의 보수의 범위는 비대칭적이다
표현 가능한 정수의 범위를 UMax(w), TMin(w), TMax(w)로 표시함
|TMin| = |TMax| + 1, TMin에 대해서는 대응되는 양수 값이 없다
이런 사실로 인해 2의 보수 산술연산에서는 기이한 특성을 갖게 되며
난해한 프로그램 오류의 원인이 될 수 있음
-
0이 비음수이므로 이것은 양수의 개수보다 1 적다는 것을 의미
-
비부호형 최대값은 2의 보수 최대값의 두 배보다 1 크다 -> UMax = 2TMax + 1
4비트 기준 최대값(TMax) = 0111 = 7, 비부호형의 최대값(UMax) = 1111 = 15
C 표준에서는 부호형 정수를 2의 보수 형식으로 나타낼 것을 요구하지는 않지만,
거의 모든 컴퓨터에서 요구하고 있다
호환성을 고려하는 프로그래머라면, 범위를 넘어가는 값의 특정 범위를 가정해서는 안되며
부호형 수에 대해서 특정 표시를 가정해서도 안 된다
C 라이브러리
INT_MAX, INT_MIN, UINT_MAX를 정의해서 부호형과 비부호형 정수의 범위를 설명하고 있다
Index
비부호형과 부호형 간의 변환
C는 서로 다른 숫자 데이터 타입들 간에 캐스팅(casting)을 허용함
음수값을 비부호형으로 전환하면 0이 될 수도 있고
비부호형 값을 2의 보수로 변환하면 TMax가 될 수도 있다
unsigned u = 4294967295u;
int tu = (int) u;
printf("u = %u, tu = %d \n", u, tu);
2의 보수 컴퓨터에서 실행할 때, 다음과 같은 결과가 출력된다
u = 4294967295, tu = -1
u는 32비트 2진수로 0xFFFFFFFF이다
이것을 int로 캐스팅하게 되면 2의 보수로 -1이 된다
숫자 값은 변할 수 있지만, 비트 패턴은 변하지 않는다
C에서 부호형과 비부호형의 비교
일반적으로 대부분의 수들은 기본적으로 부호형이다
상수 12345나 0x1A2B를 선언할때 이 값은 부호형으로 간주된다
12345u, 0x1A2Bu와 같이 문자 “U”나 “u”를 접미어로 추가하면 비부호형 상수로 만들게 된다
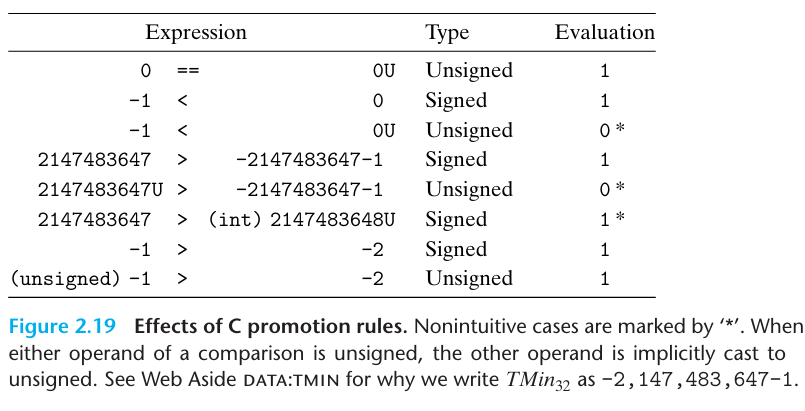
비교 오퍼랜드 중 하나가 비부호형이면, 다른 하나는 묵시적으로 비부호형으로 cast된다
수의 비트 표시를 확장하기
비부호형 수를 보다 길이가 긴 데이터 타입으로 변환하기 위해서 단순히 앞에 0들을 추가할 수 있다
이것을 영의 확장(zero extension)이라고 한다
2의 보수를 보다 긴 데이터 타입으로 변환하려면 규칙은 부호 확장(sign extension)이라 한다
short sx = -12345;
unsigned uy = sx;
printf("uy = %u:\t", uy);
show_bytes((byte_pointer) &uy, sizeof(unsigned))
빅 엔디안 머신에서 다음과 같이 출력해준다
uy = 4294954951: ff ff cf c7
short에서 unsigned로 변환할 때,
프로그램이 먼저 크기를 바꾸고 다음에 자료형을 바꾼다는 것을 보여준다
-
크기 확장(promotion: short -> int)
-
자료형 변경(int -> unsigned)
숫자의 절삭
int x = 53191;
short sx = (short) x; /* -12345 */
int y = sx; /* -12345 */
x를 short로 타입 변환(casting) 할 때 32비트 int를 16비트 short로 절삭한다
수를 절삭하면 값이 바뀔 수 있음 이것은 일종의 오버플로우와 같다
Signed와 Unsigned에 관한 조언
부호형을 비부호형으로 묵시적인 타입 변환을 하면 직관적이지 않은 동작을 보이고
직관적이지 못한 특징들로 프로그램 버그가 발생하기도 하고, 묵시적 타입 변환의
미세한 효과로 인해서 생기는 버그들은 알아내기 상당히 어려울 수 있다
C 이외의 다른 언어들은 unsigned 정수를 지원하지 않는다 자바는 signed 정수만을 지원하며
2의 보수 산술 연산으로 구현될 것을 요구한다
주소는 본래 unsigned여서 시스템 프로그래머들은 unsigned 타입이 유용하다고 생각함
비부호형 값들은 modular 연산, 다중정밀도 산술연산과 같이 숫자들이 워드의 배열로 표시되는 경우와
수학 패키지로 구현할 때 유용하다