컴퓨터 구조 CS:APP 1장
이 글은 Randal E. Bryant와 David R. O’Hallaron의 저서 《Computer Systems: A Programmer’s Perspective》(CS:APP)를 참고하여 작성되었습니다.
아래의 순서는 ChatGPT의 도움을 받아 작성되었습니다.
8086 (16비트) ↓ 80286 (보호 모드 추가) ↓ 80386 → IA-32 (32비트) ↓ 80486, Pentium 계열 ↓ x86-64 (AMD64 / Intel64) → 64비트 (현대 표준)
- 8086 마이크로프로세서 (1978)
- 16비트 아키텍처
-
인텔의 x86 아키텍처의 출발점
-
세그먼트 레지스터 사용
- 80286 (286)
- 여전히 16비트지만, 프로텍티드 모드 도입
- 80386 (386)
- IA-32 (x86 32비트) 등장
-
32비트 워드 구조
-
가상 메모리, 보호 모드, 링 구조 지원
- IA-32 계열 발전
- 80486 → Pentium → Pentium Pro → Core 시리즈
-
여전히 32비트 기반
-
Core 2 Duo부터 64비트 지원
- x86-64 (AMD64, Intel64)
- 64비트 확장 아키텍처
-
AMD가 처음 설계, 이후 인텔이 채택
-
레지스터 확장(RAX, RBX 등), 64비트 주소 공간
-
현대 PC, 서버의 주류 아키텍처
오늘날 대부분의 컴퓨터는 x86-64 아키텍처를 기반으로 동작
트랜지스터를 단일 칩에 더 많이 집적할 수 있게 되면서, 계산 능력과 메모리 주소 공간이 비약적으로 향상된 결과
컴퓨터에서의 산술 연산은 시스템의 정확성과 성능에 직접적인 영향을 미치기 때문에, 그 작동 원리를 올바르게 이해하는 것이 중요하다
(x < y)를 (x - y < 0)으로 대체할 수 없는 이유 : 오버플로우의 가능성
(-y < -x)와 같은 수식으로도 대체하지 못함 :
- 이는 2의 보수 표현 방식에서 음수와 양수의 범위가 비대칭적이기 때문이다. 예를 들어, 8비트 정수에서 -128은 표현 가능하지만 +128은 표현할 수 없다.
정보는 비트와 컨텍스트로 이루어진다
-
소스 프로그램은 0 또는 1로 표시되는 비트들의 연속
-
바이트라는 8비트 단위로 구성
-
대부분 시스템은 텍스트 문자 -> 아스키(ASCII) 표준을 사용
프로그램은 다른 프로그램에 의해 다른 형태로 번역된다
-
c를 시스템에서 실행 시키려면 저수준 기계어(인스트럭션)들로 번역되어야 한다
-
인스트럭션들은 어셈블리 단계에서 목적 파일로(.o)이라고 하는 형태로 합쳐져서 링커에 의해 결합되어 최종적으로 바이너리(exe) 디스크 파일로 저장된다
-
인스트럭션은 CPU가 이해하고 실행할 수 있는 기본 연산 명령어를 의미하며, 어셈블리는 이러한 인스트럭션을 사람이 읽고 쓰기 쉽게 기호화한 저수준 프로그래밍 언어
리눅스에서 해당 명령어를 사용하면
linux> gcc -o hello hello.c
hello.c -> hello.exe
(.c -> .i) 전처리기
↓
(.i -> .s) 컴파일러
↓
(.s -> .o) 어셈블러
↓
(.o -> .exe) 링커
→ 위 과정을 모두 합친 것이 ‘컴파일 시스템’이다
- 전처리 단계(cpp)
C 프로그램을 #문자로 시작하는 디렉티브에 따라 수정
시스템 헤더파일인 stdio.h를 프로그램 문장에 직접 삽입하라고 지시 - 컴파일 단계(ccl)
.i를 .s로 번역하며 이 파일에는 어셈블리어 프로그램이 저장된다
main:
subq $8, %rsp
movl $.LC0, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret
-
어셈블리 단계(as)
.s를 기계어 인스트럭션으로 번역하고, 이들을 재배치가능 목적프로그램의 형태로 묶어서 .o라는 목적파일에 그 결과를 저장 -
링크 단계(ld)
printf.o(표준 라이브러리)와 hello.o 파일과 결합 그 결과로 실행파일로 메모리에 적재된 이후 시스템에 의해 실행
Index
컴파일 시스템에 대한 이해가 필요한 이유
- 프로그램 성능 최적화하기 위하여 소스 코드들을
기계어 코드로 어떻게 번역하는지 알 필요가 있다- 예를 들어 switch 문 vs if-else 문 어떤게 효율적인가?
- 함수 호출 시 발생하는 오버헤드는 얼마나 되는가?
- while 루프는 for 루프보다 더 효율적일까?
- 포인터 참조가 배열 인덱스보다 더 효율적인가?
- 합계를 지역변수에 저장하면 참조 형태로 넘겨받은 인자들을
사용하는 것보다 왜 루프가 더 빨리 실행되는가? - 수식 연산시 괄호를 단순히 재배치 하기만 해도 함수가 더 빨리 실행되는 이유는?
컴파일러가 코드를 어떻게 번역하는지 이해 -> 더 빠른 코드 작성 가능
- 링크 에러 이해하기 위하여
- 링커가 참조를 풀어낼 수 없다고 할때 무엇을 의미하는가?
- 정적변수와 전역변수의 차이는?
- 다른 파일에 동일한 이름의 두 개의 전역변수를 정의한다면?
- 정적 라이브러리와 동적 라이브러리의 차이는?
- 컴파일 명령을 쉘에서 입력할 때 명령어 라인의 라이브러리들의 순서는 무슨 의미가 있는가?
- 왜 링커와 관련된 에러들은 실행하기 전까지는 나타나지 않는걸까?
여러 파일로 구성된 프로젝트에서 연결 오류를 해결하려면 링커의 동작 원리와 심볼 처리 방식에 대한 이해가 필요
- 보안 약점(Security Hole)을 파악하기 위하여
-
버퍼 오버플로우의 취약성인 인터넷과 네트워크상의 보안 약점의 주요 원인인데 이 취약성의 이유는 프로그래머가 신뢰할 수 없는 곳에서
획득한 데이터의 양과 형태를 주의 깊게 제한해야 할 필요를 거의 인식하지 못했기 때문
-> 프로그램 스택에 데이터와 제어 정보가 저장되는 방식을 이해가 필요메모리 구조(스택, 힙)와 함수 호출 구조 이해 -> 취약점 회피 가능
-
버스(Buses)
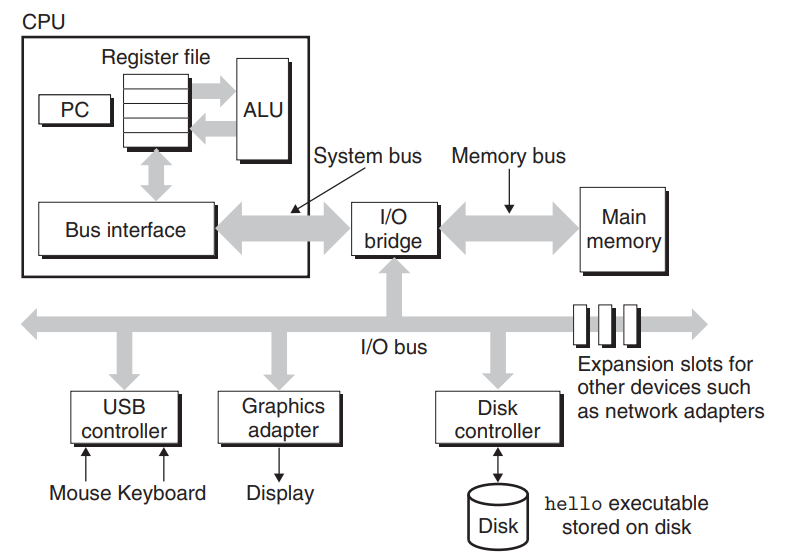
시스템 내를 관통하는 전기적 배선군 = 버스(bus)
버스는 컴포넌트들 간에 바이트 정보를 전송하고
워드라고 하는 고정 크기의 바이트 단위로 데이터를 전송하도록 설계
한 개의 워드를 구성하는 바이트 수는 시스템마다 보유하는 기본 시스템 변수이다
워드의 크기 = 4바이트(32비트) or 8바이트(64비트)
입출력 장치
그림의 시스템은 4개의 입출력 장치가 있다
- 입력용 키보드와 마우스
- 출력용 디스플레이
- 데이터와 프로그램 장기저장을 위한 디스크 드라이브
각 입출력 장치는 입출력 버스 or 컨트롤러 or 어댑터를 통해 연결된다
컨트롤러 = 디바이스 자체가 칩셋 or 시스템의 머더보드에 장착된 구성요소
어댑터 = 머더보드의 슬롯에 장착되는 카드
컨트롤러와 어댑터 공통된 목적 = 입출력 버스와 장치들 간에 정보 교환을 중개
메인 메모리
메인 메모리는 프로세서가 프로그램을 실행하는 동안 데이터와 프로그램을 모두 저장하는 임시 저장장치
물리적인 메인 메모리 = DRAM(Dynamic Random Access Memory)
논리적인 메모리 = 연속적인 바이트들의 배열, 각각 0부터 시작해서 고유의 주소(배열의 인덱스)를 가지고 있다
프로세서
주처리장치(CPU) 또는 프로세서는 메인 메모리에 저장된 인스트럭션들을 해독(실행)하는 엔진
프로세서 중심에는 워드 크기의 레지스터인 프로그램 카운터(PC)가 있다
프로세서는 전원이 켜질때부터 꺼질때까지 프로그램 카운터가 가리키는 곳의 인스트럭션을
반복적으로 실행하고 PC값이 다음 인스트럭션의 위치를 가리키도록 업데이트 한다
PC가 가리키는 메모리로부터 인스트럭션을 읽어와서 비트들을 해석하여 동작을 실행하고
PC를 다음 인스트럭션 위치로 업데이트 한다. 이 위치는 이전 위치와 연속적일 수도 있고 아닐 수도 있다
이 인스트럭션 과정들은 메인 메모리, 레지스터 파일, 수식/논리 처리기(ALU) 주위를 순환한다
레지스터 파일은 고유의 이름을 갖는 워드 크기의 레지스터 집합으로 구성되어 있다
| 적재(Load): 메인 메모리 -> 레지스터 | 한 바이트 또는 워드를 이전 값에 덮어쓰는 방식으로 복사 |
| 저장(Store): 레지스터 -> 메인 메모리 | 한 바이트 또는 워드를 이전 값을 덮어 쓰는 방식으로 복사 |
| 작업(Operate): 두 레지스터의 값을 ALU로 복사 | 두 개의 워드로 수식연산을 수행 후 결과를 덮어쓰기 방식 레지스터 |
| 점프(Jump): 인스트럭션 자신 | 한 개의 워드를 추출하고 이것을 PC에 덮어쓰기 방식으로 복사 |
.”\hello”를 입력했을때 내부 과정
Keyboard -> USB Controller -> I/O Bridge -> Bus Interface -> Register File -> System Bus -> Memory Bus -> Main Memory “hello”
실행 파일 hello를 디스크에서 메인 메모리로 로딩 과정
Disk -> Disk Controller -> I/O Bridge -> Main Memory // hello code “hello, world\n”
출력 스트링을 메모리에서 화면으로 기록하는 과정
Main Memory // hello code “hello, world\n” -> Memory Bus -> System Bus -> Register File -> Bus Interface -> I/O Bridge -> I/O Bus -> Graphics Adapter -> Display // “hello, world\n”
Index
캐시가 중요하다
- 물리적인 법칙 때문에 큰 저장장치들은 작은 저장장치들보다 느린 속도를 갖는다
더 빠른 장치들은 느린 장치들보다 만드는데 더 많은 비용이 든다 -
디스크 드라이브는 메인 메모리보다 1000배 이상 크기가 더 크지만 1 워드의 데이터를
읽어오는데 걸리는 시간은 메모리에서보다 디스크에서 천만 배 더 걸린다 - 메인 메모리를 더 빠르게 만드는 것보다 프로세서를 더 빠르게 만드는 것이 더 쉽고 비용이 적게 든다
캐시 메모리는 프로세서가 단기간에 필요로 할 가능성이 높은 정보를 임시로 저장할 목적으로 사용
| L1 캐시 | 수천 바이트의 데이터를 저장, 레지스터 파일만큼 빠른 속도로 액세스 |
| L2 캐시 | 수백 킬로바이트에서 수 메가 바이트 용량을 가지며 프로세서와 전용 버스를 통해 연결 |
-
프로세서가 L2 캐시를 액세스할 때 L1 캐시보다 5배 정도 느림
하지만 메인 메모리를 액세스 할때보다 L2 캐시를 액세스할 때 5배에서 크게는 10배까지 빠르다 -
L1, L2 캐시는 SRAM이라는 하드웨어 기술을 이용하여 구현
L1, L2, L3 캐시 시스템의 아이디어는 프로그램이 지엽적인 영역의 코드와 데이터를 액세스하는 경향인 지역성(locality)을 활용하여 시스템이 매우 크고 빠른 메모리 효과를 얻을 수 있다는 것
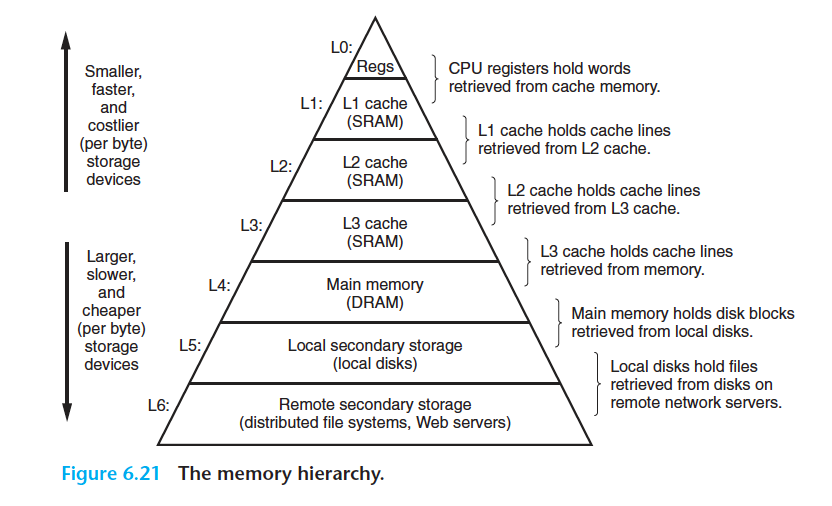
저장장치들은 계층구조를 이룬다
-
위 그림 계층의 꼭대기에서부터 맨 밑바닥까지 이동할수록 저장장치들은 더 느리고, 더 크고, 바이트당 가격이 싸진다
-
레지스터 파일은 레벨 0, L1 ~ L3는 레벨 1에서 3까지 캐시를 사용하는 구조, 메인 메모리는 레벨 4에 위치
-
계층구조의 주요 아이디어는 레벨의 저장장치가 다음 하위레벨 저장장치의 캐시 역할을 한다는 것
L1과 L2의 캐시 -> 각각 L2와 L3 캐시이다
Index
운영체제는 하드웨어를 관리한다
프로그램이 장치나 메인 메모리에 직접 엑세스하지 않음
응용프로그램이 하드웨어를 제어하려면 언제나 운영체제(Operating System)를 통해서 해야 한다
운영체제의 목적
-
응용프로그램들이 하드웨어를 잘못 사용하는 것을 막기 위해
-
프로그램들이 단순하고 균일한 매커니즘 사용하여 복잡하고 매우 다른 저수준 하드웨어 장치들을 조작할 수 있도록 하기 위해
이 두가지 목표를 아래와 같은 추상화를 통해 이루어진다
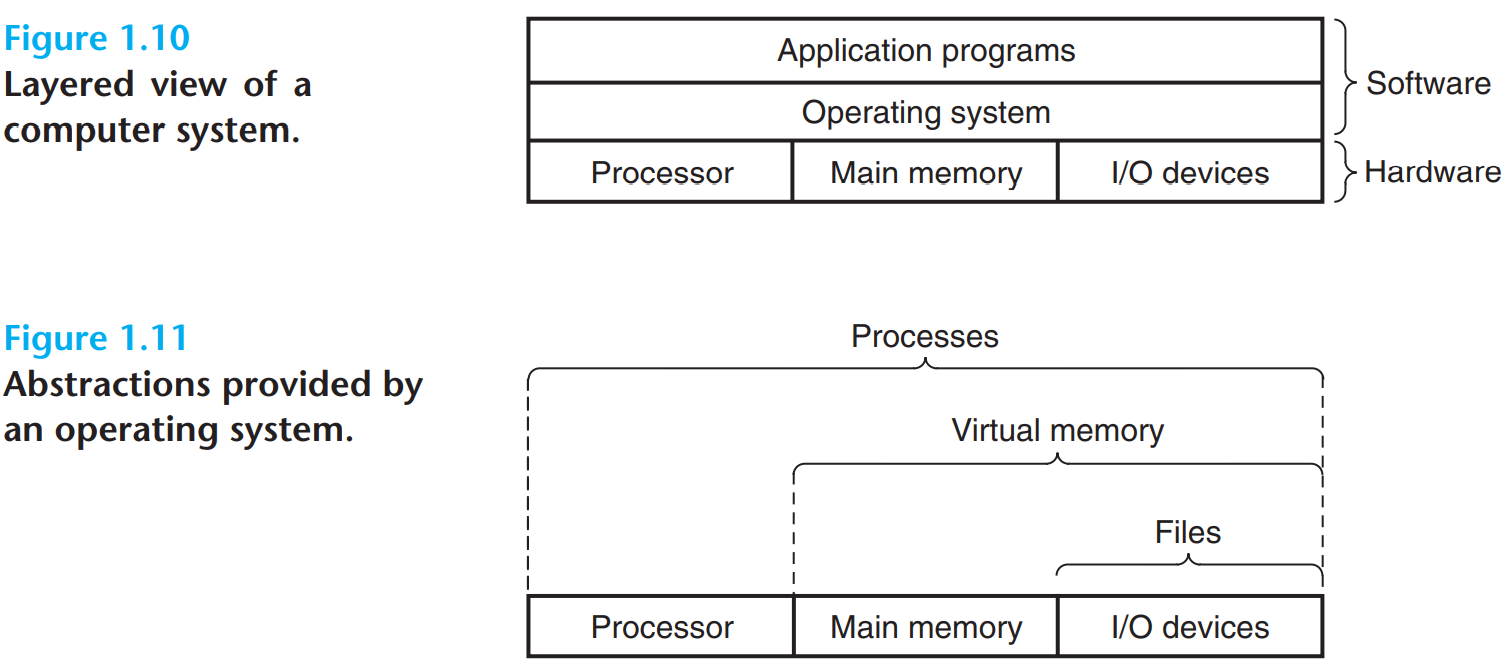
프로세스
프로세스는 프로그램에 대한 운영체제의 추상화
다수의 프로세스들은 동일한 시스템에서 동시에 실행될 수 있음
동시에(concurrently)라는 말은 한 프로세스의 인스트럭션들이 다른 프로세스의 인스트럭션들과 섞인다는 것을 의미
운영체제는 문맥 전환(Context Switching)을 사용하여 교차실행을 수행
컨텍스트라고 부르는 상태정보(PC, 레지스터 파일, 메인 메모리의 현재 값)을 이용하여 운영체제는 프로세스를 추적
운영체제는 현재 프로세스의 컨텍스트를 저장하고 새 프로세스의 컨텍스트를 복원시키는 문맥전환을 실행하여 제어권을 새 프로세스에 넘겨줌
프로그램을 실행하면 쉘은 시스템 콜이라는 특수 함수를 호출함
운영체제는 쉘의 컨텍스트를 저장한 뒤, 새로운 프로세스와 컨텍스를 생성 -> 제어권을 새로운 프로세스로 넘겨줌
실행하던 프로그램 종료 -> 운영체제는 쉘 프로세스 컨텍스트 복구 -> 제어권을 넘겨주며 다음 명령어를 기다림
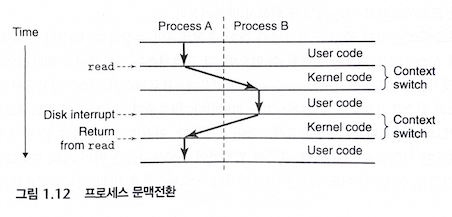
프로세스에서 다른 프로세스로의 전환은 운영체제 커널에 의해 관리
커널(kernel)은 운영체제의 코드의 일부분으로서 메모리에 상주함
응용 프로그램 -> 운영체제 -> 파일 읽기나 쓰기 같은 특정 시스템콜을 실행 -> 커널에 제어를 넘김
커널은 요청된 작업을 수행 -> 응용 프로그램으로 리턴 (쉘은 프로세스이지만, 커널은 별도의 프로세스가 아님)
쓰레드(Thread)
프로세스가 쓰레드라고 하는 다수의 실행 유닛으로 구성
각 쓰레드는 프로세스의 컨텍스트에서 실행, 동일한 코드와 전역 데이터를 공유
다수의 프로세스들에서보다 데이터의 공유가 더 쉽다
쓰레드가 프로세스보다 더 효율적이다
가상메모리
각 프로세스들이 메인 메모리 전체를 독점적으로 사용하고 있는 것 같은 환상을 제공하는 추상화가 가상메모리이다
리눅스에서, 주소공간의 최상위 영역은 모든 프로세스들이 공통으로 사용하는 운영체제의 코드와 데이터를 위한 공간
리눅스 프로세스들의 가상주소 공간이 아래 그림처럼 나와있다
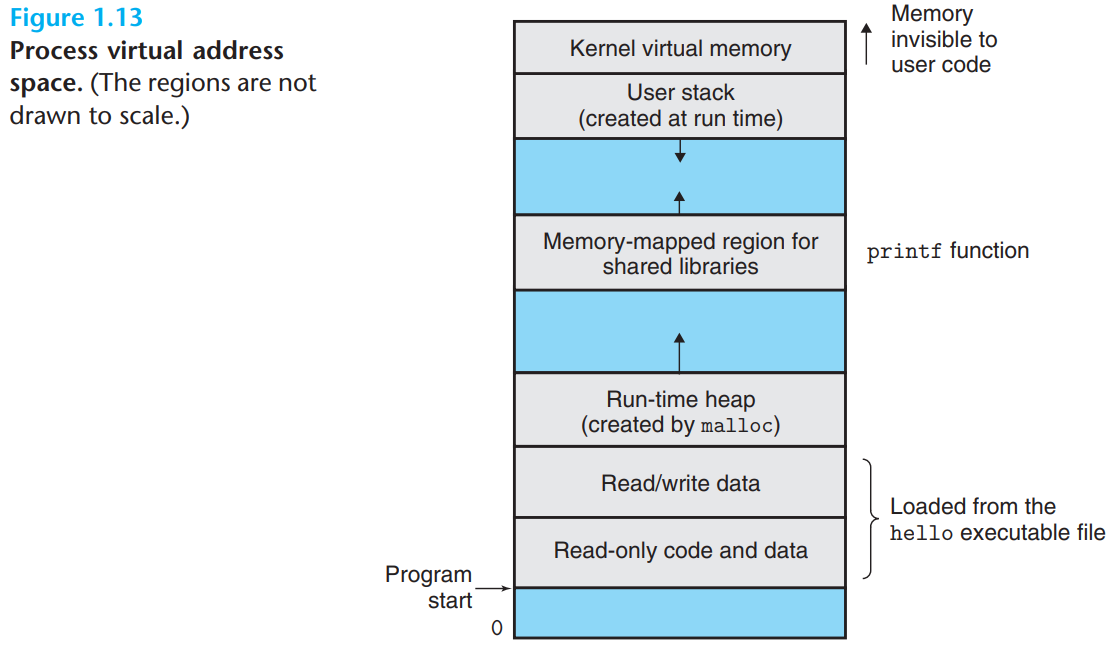
-
프로그램 코드와 데이터: 모든 프로세스들이 같은 고정 주소에서 시작하며, 다음에 C 전역변수에 대응되는 데이터 위치들이 따라옴
-
힙 Heap: 힙은 프로세스가 실행되면서 C 표준함수인 malloc이나 free를 호출하면서 런타임에 동적으로 그 크기가 늘었다 줄어듦
-
공유 라이브러리: 주소공간 중간 부근에 C 표준 라이브러리나 수학 라이브러리와 같은 공유 라이브러리의 코드와 데이터를 저장하는 영역이 있음
-
스택: 사용자 가상 메모리 맨 위, 컴파일러가 함수 호출을 구현하기 위해서 사용하는 사용자 스택이 위치, 힙과 마찬가지로 동적임 (함수 호출시 늘었다가 리턴할때 줄어듬)
-
커널 가상메모리: 주소공간 맨 윗부분은 커널을 위해 예약되어 있음
응용 프로그램들이 이 영역의 내용을 읽거나 쓰는 것을 금지(이런 작업을 수행하기 위해서는 커널을 호출해야 함)
파일
파일 = 연속된 바이트들 모든 입출력장치는 파일로 모델링함
-
시스템의 모든 입출력은 유닉스 I/O라는 시스템 콜을 이용하여 파일을 읽고 쓰는 형태로 이루어짐
-
다양한 입출력장치들을 파일이라는 통일된 관점을 제공함
Index
시스템은 네트워크를 사용하여 다른 시스템과 통신한다
네트워크는 아래 그림처럼 단지 또 다른 입출력장치로 볼 수 있다
시스템이 메인 메모리부터 네트워크 어댑터로 일련의 바이트를 복사할 때,
데이터는 로컬디스크 드라이브 대신에 네트워크를 통해서 다른 컴퓨터로 이동된다
telnet을 예를 들자면
문자열을 telnet 클라이언트에 입력 -> 클라이언트 프로그램에서 telnet 서버 전송 ->
telnet 서버가 네트워크에서 스트링을 받음 -> 원격 쉘 프로그램에 전송 ->
원격 쉘은 프로그램을 실행하고 출력을 telnet 서버 ->
telnet 서버는 네트워크를 거쳐 받은 문자열을 telnet 클라이언트로 전달 ->
클라이언트 프로그램은 출력 스트링을 자신의 로컬 터미널에 표시
중요한 주제들
중요한 아이디어는 시스템이라는 것은 단지 하드웨어 그 이상의 것이라는 점
응용프로그램의 실행이라는 궁극의 목적을 달성하기 위해 협력해야 하는 하드웨어와 시스템 소프트웨어가 서로 연결된 것을 말한다
Amdahi의 법칙
Gene Amdahl은 시스템의 일부 성능 개선의 효율성에 대한 관찰을 함
주요 아이디어는 우리가 어떤 시스템의 한 부분의 성능을 개선할 때,
전체 시스템 성능에 대한 효과는 그 부분이 얼마나 빨라졌는가에 관계됨
\[\text{S} = \frac{1}{(1 - α) + \frac{α}{k}}\]
전체 시간의 60%(α = 0.6)만 소모한 이 시스템의 일부분이 3배(k = 3) 속도가 빨라진다고 생각해보자
\[\frac{1}{(0.4 + \frac{0.6}{3})} = 1.67\]속도 향상은 1.67이다
\[\text{S}\infty = \frac{1}{(1 - α)}\]
시스템의 60%를 시간이 거의 걸리지 않는 지점까지 올릴 수 있다면 총 속도 개선율은 1/0.4 = 2.5배밖에 되지 않음
성능을 2배 이상으로 개선할 수 있다면, 컴퓨터 세계에서 가장 의미가 있다
Index
동시성과 병렬성
동시성(concurrency): 다수의 동시에 벌어지는 일을 갖는 시스템에 관한 일반적인 개념
병렬성(parallelism): 동시성을 사용해서 시스템을 보다 빠르게 동작하도록 하는 것을 말함
쓰레드 수준 동시성
쓰레드를 이용하면 -> 한 개의 프로세스 내에서 다수의 제어흐름을 가질 수도 있다
1960년대 초반 시간공유(time-sharing) 기법의 출현
한 개의 프로세서로 빠르게 전환하는 방법을 사용하는 것을 단일 프로세서 시스템이라고 한다
어떤 시스템이 여러 개의 프로세서를 가지고 운영체제 커널의 제어 하에 동작하는 경우를 멀티프로세서 시스템이라고 한다
최근에는 멀티코어 프로세서들과 하이퍼쓰레딩(Hyperthreading) 기법의 출현
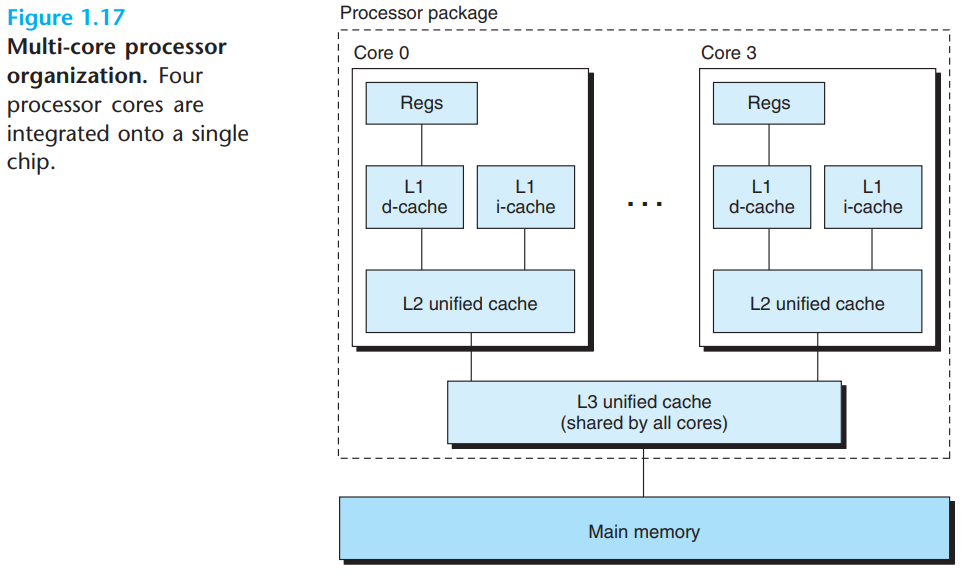
멀티쓰레딩이라고도 하는 하이퍼쓰레딩은 하나의 CPU가 여러 개의 제어 흐름을 실행할 수 있게 해주는 기술
기존의 프로세서의 쓰레드들 간의 전환하는데 2만 클럭 사이클이다
하이퍼쓰레드 프로세서에서는 매 사이클마다 실행할 쓰레드를 결정함
쓰레드가 데이터를 캐시에 로딩하기 위해 대기해야 한다면, CPU는 다른 쓰레드를 실행할 수 있음
멀티프로세싱의 이용은 시스템 성능을 두 가지 방법으로 개선
-
다수의 태스크를 실행할 때, 동시성을 시뮬레이션할 필요를 줄어준다
-
멀티 프로세싱으로 응용프로그램을 빠르게 실행할 수 있음(프로그램이 병렬로 효율적으로 실행할 수 있는 멀티쓰레드의 형태일것)
인스트럭션 수준 병렬성
인스트럭션 수준 병렬성 : 훨씬 낮은 수준에서의 추상화로 여러 개의 인스트럭션을 한 번에 실행 가능
초기 마이크로프로세서들은 한 개의 인스트럭션 실행 -> 3.1개의 클럭 사이클 필요
최근의 프로세서들은 매 클럭 사이클마다 2.4개의 인스트럭션 실행 가능
파이프라이닝에서는 인스트럭션을 실행하기 위해 요구되는 일들을 여러 단계로 나누고 프로세서 하드웨어가
일련의 단계로 구성되어 이들 단계를 하나씩 각각 수행함
사이클당 한 개 이상의 인스트럭션을 실행 가능 프로세서 -> 슈퍼스케일러(super-scalar)
싱글 인스트럭션, 다중 데이터 병렬성(SIMD)
최신 프로세서들은 최하위 수준에서 싱글 인스트럭션, 다중 데이터, SIMD 병렬성이라는 모드로
한 개의 인스트럭션이 병렬로 다수의 연산을 수행할 수 있는 특수 하드웨어를 가지고 있음
SIMD 인스트럭션들 영상, 소리, 동영상 데이터 처리를 위한 응용 프로그램의 속도를 개선하기 위해 제공
컴퓨터 시스템에서의 추상화의 중요성
좋은 프로그래밍 연습의 하나는 함수들을 간단한 응용프로그램 인터페이스 API로 정형화 하는 것
프로그래머가 그 내부의 동작을 고려하지 않으면서 코드를 사용할 수 있도록 함
운영체제 측면에서 세 가지 추상화 소개
-
프로세스는 실행 중인 프로그램의 추상화
-
파일을 입출력의 장치의 추상화
-
가상메모리는 프로그램 메모리의 추상화
한 개 더 예를 들자면 가상머신이 있다
- 1장 요약 -
-
컴퓨터 시스템 응용 프로그램이 필요한 것 -> 하드웨어, 시스템 소프트웨어
-
프로그램은 ASCII 문자로 시작 -> 컴파일러와 링커에 의해 바이너리 실행파일들로 번역함
-
프로세서는 메인 메모리에 저장된 바이너리 인스트럭션을 읽고 해석함
-
컴퓨터는 대부분의 시간을 메모리, 입출력장치, CPU 레지스터 간에 데이터를 복사하는 데 씀
-
시스템의 저장장치들은 계층구조를 형성하여 CPU 레지스터가 최상위,
하드웨어 캐시 메모리, DRAM 메인 메모리 디스크 저장장치 등이 순차적으로 위치한다 -
계층구조 상부의 저장장치(비싼 장치)들은 하부의 장치들을 위한 캐시 역할을 수행함
-
운영체제 커널은 응용프로그램과 하드웨어 사이에서 중간자 역할을 수행
- 운영체제는 세 가지 근본적인 추상화를 제공
- 파일은 입출력장치의 추상화다
- 가상메모리는 메인 메모리와 디스크의 추상화다
- 프로세스는 프로세서, 메인 메모리, 입출력 장치의 추상화다
- 네트워크는 단지 또 하나의 입출력장치다